Unsupervised Intelligence: Inside the Mind of an Autoencoder
8min read • 2025-10-31 Data
Data
Data
In a world where data labeling is often costly or incomplete, unsupervised learning offers powerful tools for uncovering hidden patterns without prior knowledge of the ground truth. Among these tools, autoencoders have emerged as a cornerstone for dimensionality reduction, noise removal, and anomaly detection.
This article introduces the fundamental principles of autoencoders — how they work, why they are useful, and how they can be leveraged in real-world scenarios such as fraud detection or data compression. The goal is to provide a clear understanding of their architecture and to illustrate their relevance in modern data analysis pipelines.
1. Introduction to Autoencoders
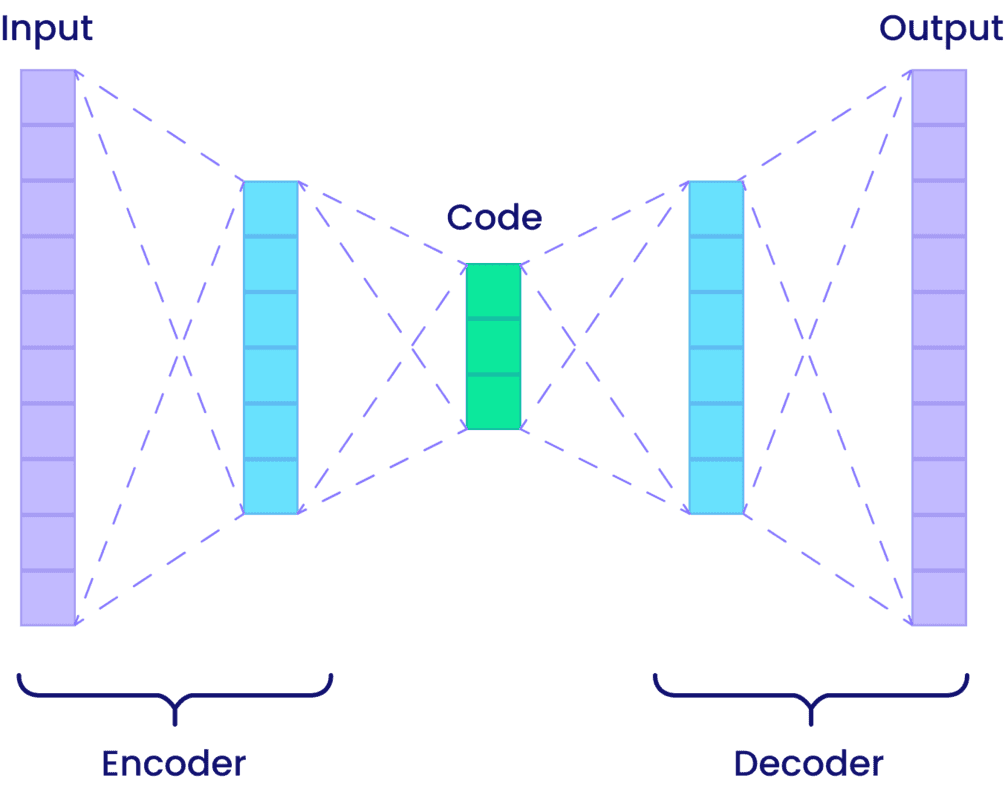
Autoencoders are a class of artificial neural networks used in unsupervised learning, meaning they do not rely on labeled data. In supervised learning, each example is associated with a label — for instance, an image of a cat labeled as “cat.” In contrast, autoencoders operate solely on the input itself.
Their primary objective is to compress input data into a lower-dimensional representation, known as the latent space, and then reconstruct it as accurately as possible. This can be compared to summarizing a long novel into a short paragraph and then rewriting the novel from that summary.
Key Concepts
- Latent Space – compact, information-rich representation of input data.
- Loss Function – quantifies the reconstruction error (often MSE).
- Unsupervised Learning – no labels are required, making it ideal for raw or unannotated data.
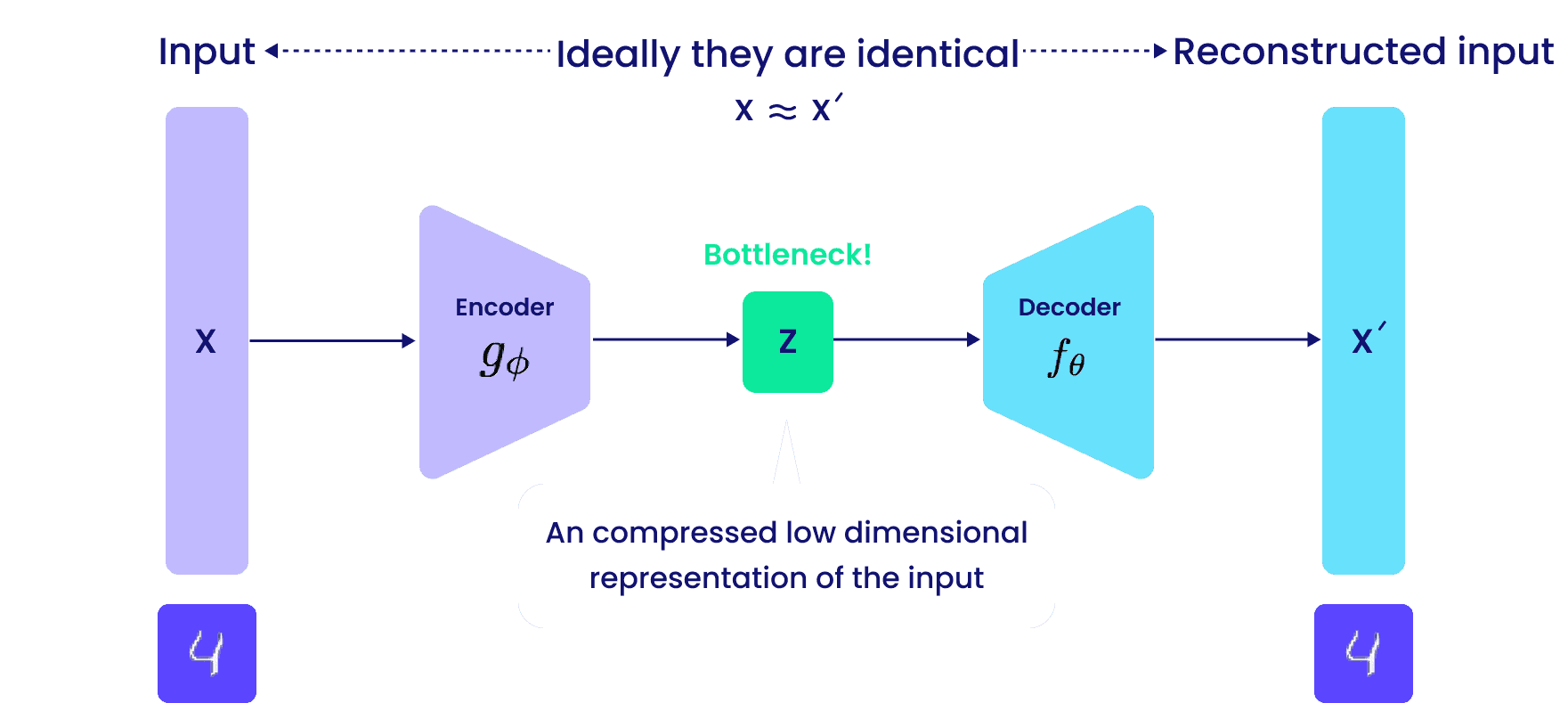
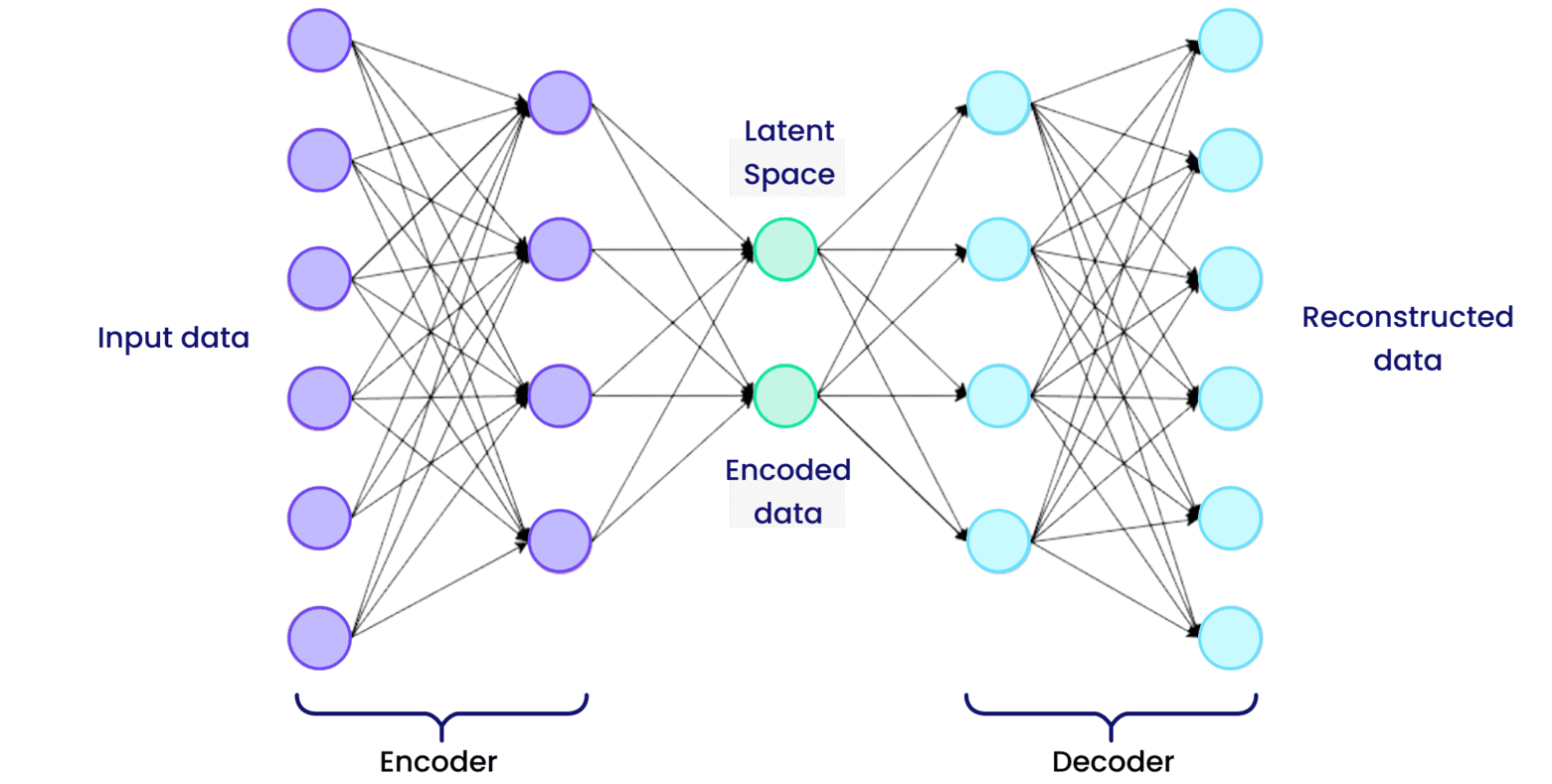
2. Autoencoder Architecture
An autoencoder’s structure resembles a sandwich, with the encoder and decoder on either side of the compressed representation at the center.
Encoder
- Input Layer: Processes raw data such as images, text, or numbers, for instance, a grayscale image of 28x28 pixels.
- Hidden Layers: Reduce data size step by step, focusing on key patterns while ignoring less critical information, such as identifying edges in an image.
- Bottleneck Layer: This represents the most compact version of the data, retaining only essential features, like the outline of a face in a photograph.
Decoder
- Bottleneck Layer: Starts with compressed data.
- Hidden Layers: Gradually reconstruct the data back to its original size, adding features like colors and textures to an image.
- Output Layer: Produces the final reconstructed data to resemble the original input as closely as possible.
Tips to Improve Autoencoders:
- Smaller Hidden Layers: Using smaller hidden layers helps the model focus on critical details and learn efficient patterns. For example, it can summarize an image by retaining only the most essential edges and shapes.
- Denoising: Train the autoencoder to remove noise by feeding it noisy input data, such as blurry photos, and tasking it with reconstructing clean versions.
- Activation Functions: Use specific mathematical formulas to influence how neurons behave, ensuring the model concentrates on the most important features effectively.
3. Types of Autoencoders
Autoencoders come in specialized variants tailored for specific tasks. Notable examples include:
- LSTM-Based Autoencoders: Designed for sequential data like text or time series, where the order of inputs matters.
- Variational Autoencoders (VAEs): Enhance standard autoencoders by adding probabilistic elements, making them suitable for tasks like data generation and uncertainty modeling.
4. LSTM-Based Autoencoders
Standard autoencoders often struggle with sequential data such as text or time series. LSTM-based autoencoders address this limitation by processing data where the sequence is significant, like stock prices or sentences in a document.
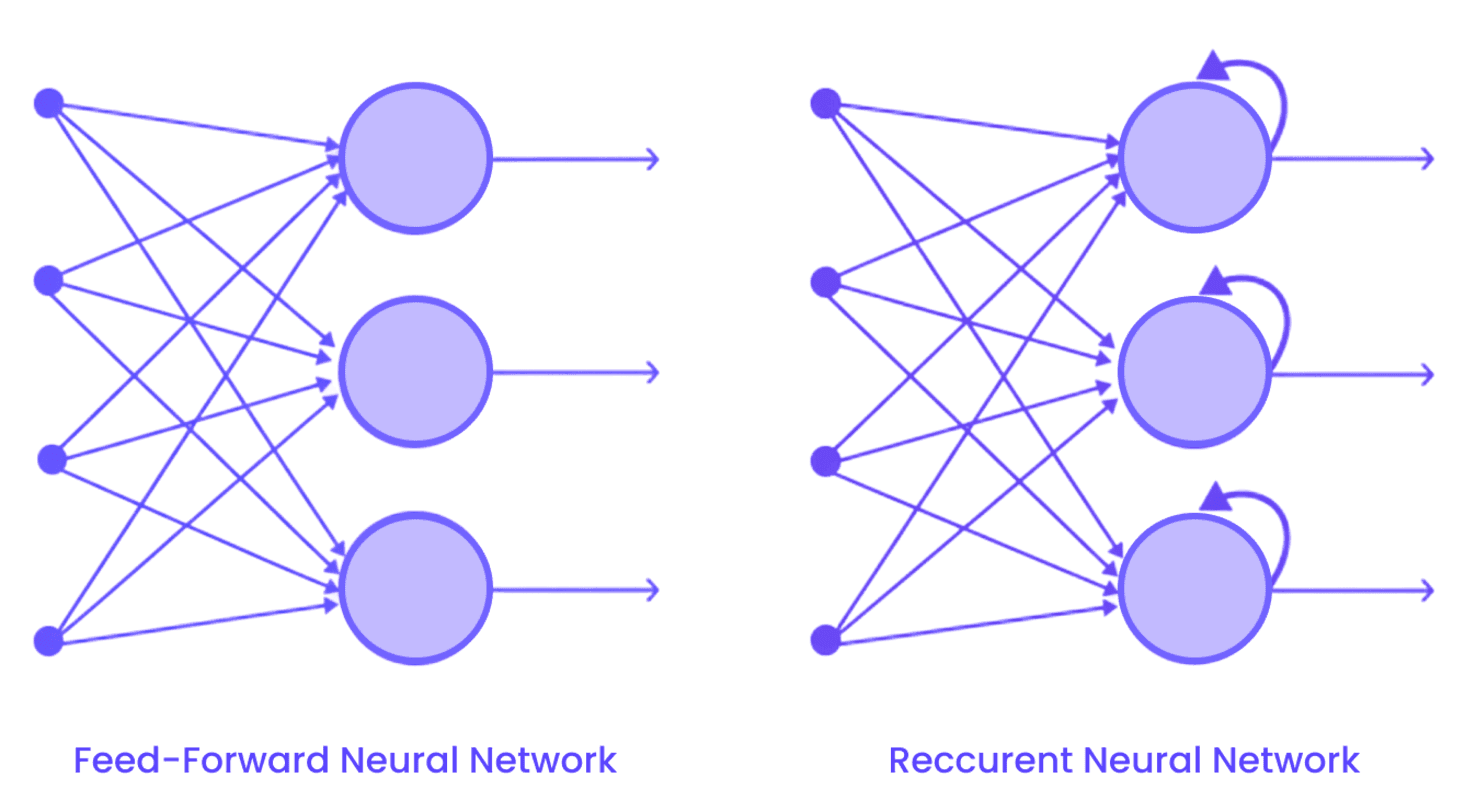
What are RNNs?
Recurrent Neural Networks (RNNs) are suited for sequence-based data as they preserve the order of inputs. They are used in:
- Time-Series Analysis: Predicting stock prices or sales trends.
- Text Processing: Understanding or generating coherent sentences.
- Speech Recognition: Converting spoken words into text.
However, traditional RNNs, or Vanilla RNNs, often struggle with long sequences due to memory limitations. Enhanced versions like GRUs (Gated Recurrent Units) and LSTMs (Long Short-Term Memory Networks) overcome this by retaining useful information across longer sequences.
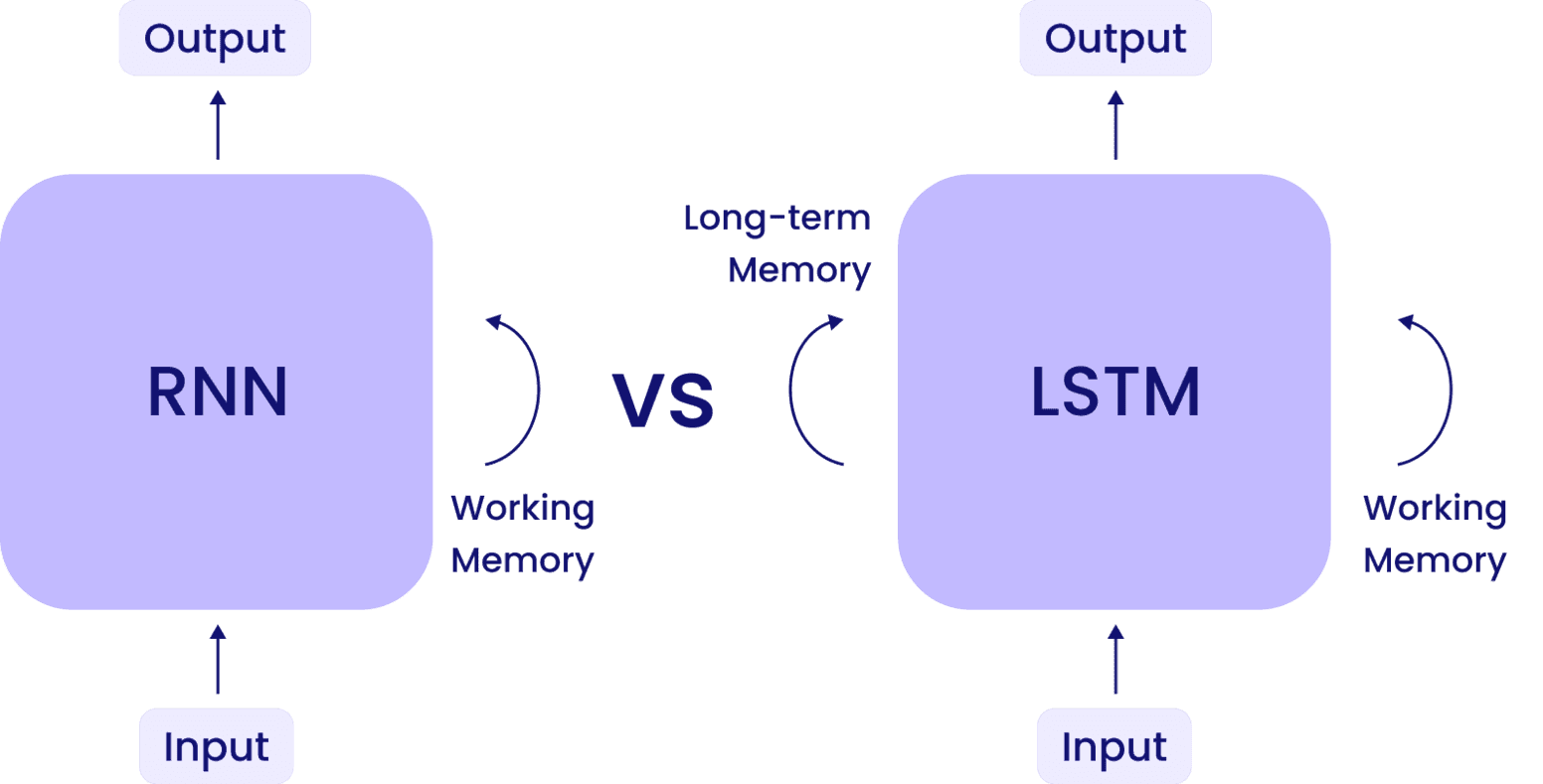
What are LSTMs?
LSTMs are specialized RNNs designed for sequential data like text or time series. Their unique architecture, with memory cells and gates, determines what information to keep, forget, or output. This makes LSTMs ideal for tasks requiring context and sequence understanding, such as language modeling or trend analysis.
What is an LSTM Autoencoder?
An LSTM-based autoencoder combines the strengths of Long Short-Term Memory (LSTM) networks and traditional autoencoders. Rather than using standard neural layers, it leverages LSTM layers to process and reconstruct sequential data, making it ideal for uncovering patterns and relationships in time-series data.
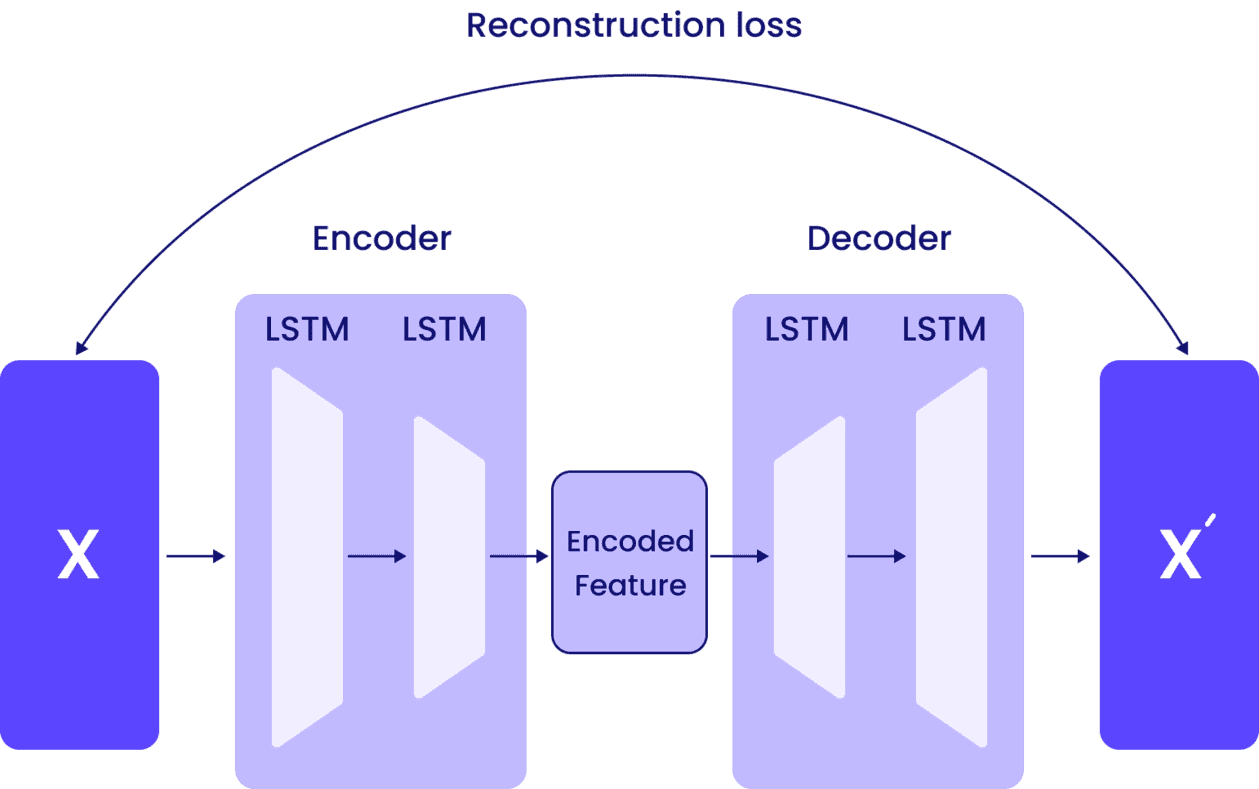
How it Works:
- LSTM Encoder: Compresses a sequence into a smaller, meaningful representation. For example, it can summarize a series of temperature readings into a trend.
- LSTM Decoder: Reconstructs the original sequence from the compressed representation, recreating all the temperature readings from the trend.
Consider a retail store analyzing customer purchasing behavior. An LSTM autoencoder can be trained on normal transaction patterns, learning how items are typically purchased together over time. If a sequence significantly deviates, such as an unusually high purchase of luxury items, the model flags it as a potential anomaly for further review.
5. Variational Autoencoders (VAEs)
While LSTM autoencoders are effective for sequential data, they produce deterministic outputs, meaning the same input always results in the same output. Variational Autoencoders (VAEs) take this further by introducing variability, generating a range of compressed representations rather than a fixed one. This capability makes VAEs particularly useful for tasks like data generation and modeling uncertainty.
How VAEs Work:
Unlike standard autoencoders, VAEs add a probabilistic component to the latent space. Instead of creating one compressed representation, they generate:
- Mean (μ): The central value of the data distribution.
- Variance (σ²): Indicates how much the data can vary around the mean.
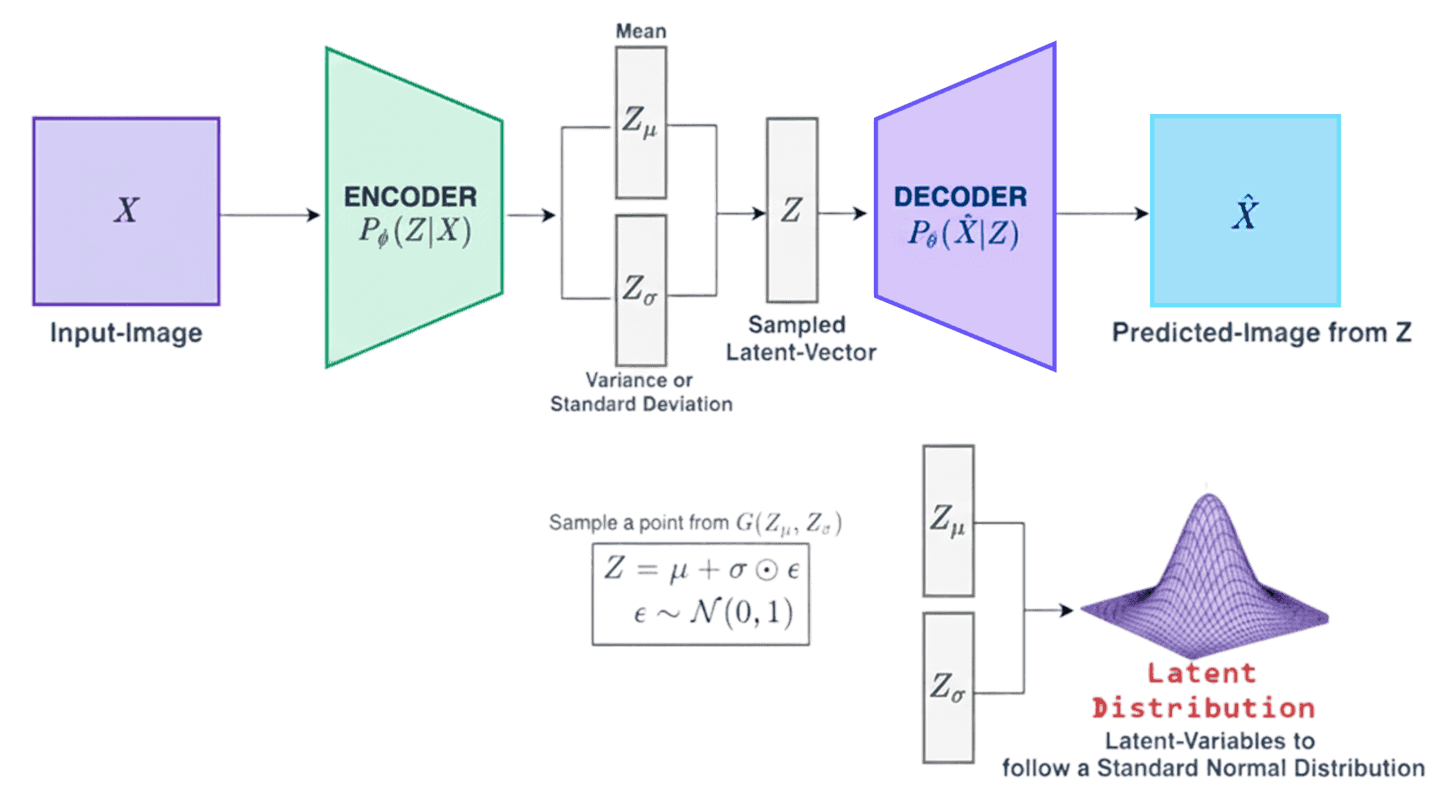
This approach allows VAEs to produce slightly different outputs each time, achieved through the reparameterization trick, which ensures variability in the reconstructions.
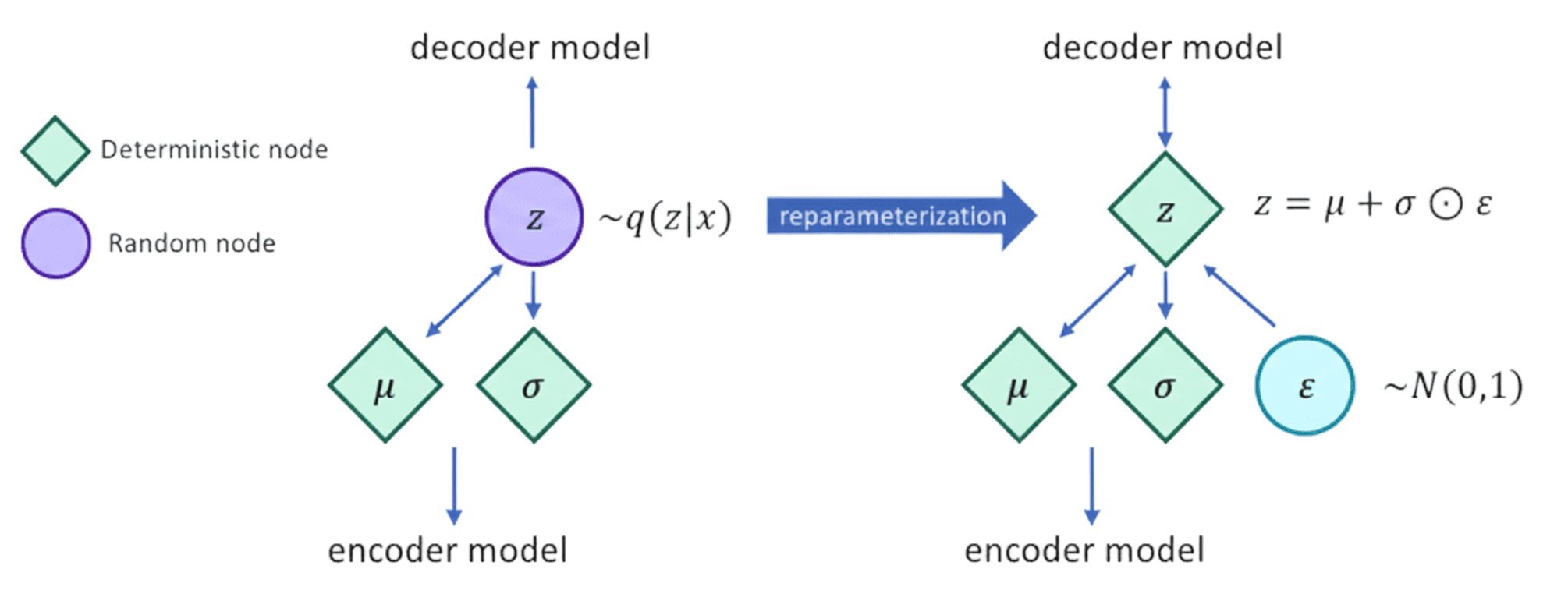
(where ε is random noise drawn from a standard normal distribution).
VAE Loss Function:
Training VAEs involves optimizing two loss components:
- Reconstruction Loss: Measures how closely the reconstructed data matches the original input. For example, it compares how similar a recreated image is to the original.
- KL Divergence: Encourages the latent space to conform to a standard normal distribution, ensuring smooth transitions and meaningful variability.
Applications of VAEs:
- Data Generation: Creating realistic images, such as human faces, from a dataset.
- Anomaly Detection: Identifying unusual patterns, such as spotting anomalies in healthcare claims.
- Uncertainty Modeling: Representing uncertainty in predictions, which is particularly useful in fields like personalized medicine.
For instance, in personalized medicine, VAEs can generate synthetic patient profiles. By learning from existing datasets, a VAE can simulate distributions of common medical variables like age, vital signs, and prevalent conditions. These synthetic profiles can enhance training datasets, improving the accuracy and reliability of healthcare machine-learning models.
Conclusion
Autoencoders—whether standard, LSTM-based, or variational—are powerful and versatile tools in machine learning. They excel in tasks like anomaly detection, data generation, and data compression. These models are critical in industries like healthcare, finance, and image processing, where efficiently compressing data into meaningful representations unlocks valuable insights. By exploring their architectures and applications, you can unlock their full potential and create impactful solutions.
Références
Michelucci, U. (2022, January 12). An Introduction to Autoencoders (arXiv preprint arXiv:2201.03898). https://arxiv.org/pdf/2201.0389
Bergmann, D., & Stryker, C. (2023, November 23). What is an autoencoder? IBM Think. https://www.ibm.com/think/topics/autoencoder
V7 Labs. (2024). Autoencoders in Deep Learning: Tutorial & Use Cases. V7 Blog. https://www.v7labs.com/blog/autoencoders-guide
















