Pourquoi votre IA est-elle plus intelligente en anglais ?
7min read • 2026-02-18 Data
Data
Data
On a tous vécu ce moment : vous posez une question complexe à un LLM en français, la réponse est correcte… mais un peu floue, moins structurée, parfois même hésitante. Vous reformulez la même question en anglais — et soudain, le modèle semble “plus intelligent”. Plus clair. Plus logique. Plus précis.
Ce n’est pas une illusion. Et ce n’est pas non plus une preuve que “l’anglais est une langue plus logique”. La vraie raison est plus subtile : entre votre question et la réponse, le modèle ne manipule pas des mots, mais des représentations numériques. Et dans cet espace interne, certaines langues — surtout l’anglais — sont souvent mieux ancrées.
Le “langage” de la réflexion : les vecteurs, pas les mots
En toute rigueur, un LLM ne “pense” pas en français, en anglais ou en arabe comme un humain. Lorsqu’il reçoit un texte, il ne l’entend pas et ne le lit pas au sens naturel du terme. Il commence par le découper en unités (des tokens), puis il transforme ces unités en vecteurs : des objets mathématiques dans un espace à très haute dimension.
Imaginez une carte gigantesque, mais au lieu de continents et de pays, elle contient des concepts, des nuances et des relations. Les idées ne sont pas stockées sous forme de définitions comme dans un dictionnaire. Elles existent comme des configurations dans cet espace. “Pomme”, “amitié”, “contrat”, “fraude”, “joie”… tout cela correspond à des zones, des directions et des proximités.
Quand vous posez une question, le modèle ne se parle pas en phrases intérieurement. Il effectue des transformations successives sur ces vecteurs pour construire, étape par étape, une représentation interne compatible avec une réponse. Puis il génère la sortie, token après token, en suivant une règle fondamentale : produire ce qui est le plus cohérent statistiquement avec le contexte.
Autrement dit : Le texte est l’interface. Le calcul se fait sur des représentations internes (vecteurs) apprises pendant l’entraînement.
L’ancrage anglais : pourquoi le centre de gravité bascule
Si le raisonnement est mathématique, pourquoi une langue serait-elle avantagée ? Parce que la carte interne du modèle n’est pas neutre. Elle est le reflet de son apprentissage.
L’entraînement d’un LLM se fait sur des corpus massifs où l’anglais est écrasant : selon l'article fondateur de GPT-3 (Brown et al., 2020), cette langue représentait 93% des données d'entraînement. À l'inverse, des langues comme le français ou l'espagnol ne constituent souvent que de faibles pourcentages. Cela crée un effet très naturel : l’espace latent développe des zones plus denses, plus structurées et mieux connectées autour de l’anglais, tout simplement parce que le modèle y a vu plus d’exemples, plus de formulations, plus de variations.
C’est là qu’apparaît une idée fascinante : sur certaines tâches de raisonnement, le modèle semble parfois utiliser l’anglais comme langue pivot. Pas parce qu’il “traduit” consciemment, mais parce que les chemins internes qui mènent à une solution robuste sont statistiquement plus stables lorsque les concepts sont alignés avec les structures dominantes de son entraînement.
C’est un réflexe de survie algorithmique : quand la difficulté augmente, le modèle se replie souvent sur ses zones les plus 'musclées', qui sont statistiquement anglophones.
Ce phénomène crée une forme de déperdition : dans une langue moins représentée, le modèle doit fournir un effort supplémentaire pour projeter vos concepts vers ses zones de connaissances les plus solides. À chaque étape de ce transfert interne, la précision s'effrite légèrement : une nuance se perd, une articulation logique se fragilise, et la conclusion finit par être moins percutante.
Une autre cause très concrète (et souvent ignorée) : la taxe de tokenisation
Il y a une seconde explication, plus mécanique, qui rend ce sujet tout de suite pertinent pour l’entreprise. Toutes les langues ne coûtent pas le même nombre de tokens.
Selon l’écriture et la manière dont le tokenizer découpe les mots, une phrase en français, en arabe ou en hindi peut nécessiter plus (ou parfois beaucoup plus) de tokens qu’une phrase équivalente en anglais.
Pour exprimer une idée simple comme "L'amitié est précieuse", voici comment un tokenizer standard (type GPT-5) la décompose selon les langues.
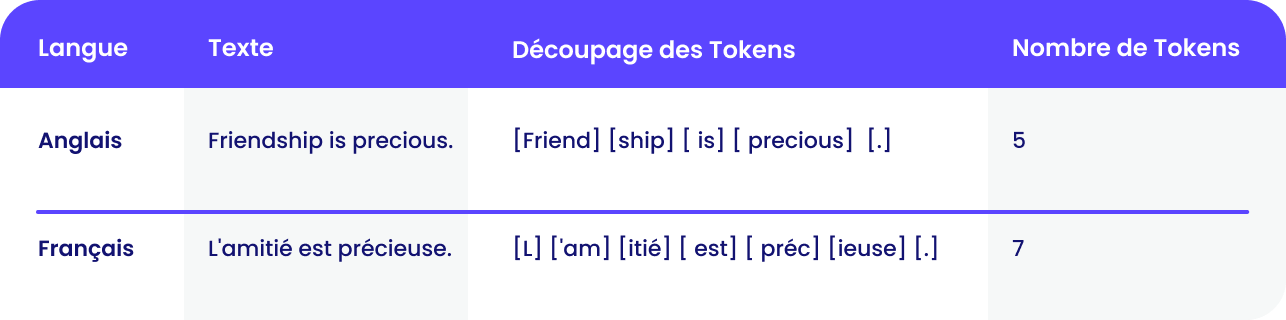
L’effet varie selon le modèle et son tokenizer, mais il est assez fréquent pour avoir un impact pratique. Comme la fenêtre de contexte est limitée, la conséquence est simple : plus une langue consomme de tokens, moins il reste de place pour le contexte utile.
C’est une taxe invisible. Elle peut augmenter le coût, réduire la capacité à traiter des documents longs, et surtout fragiliser la cohérence sur des tâches où la précision dépend du maintien d’un contexte riche.
En entreprise, cette “taxe” explique pourquoi un assistant peut être excellent sur un document en anglais, et soudain moins fiable sur un document français de même complexité : ce n’est pas seulement une question de traduction, c’est aussi une question de capacité cognitive disponible dans la fenêtre de contexte.
Est-ce que le modèle fait une traduction aller-retour ?
Pas au sens classique. Il n’ouvre pas un dictionnaire externe et ne lance pas une traduction séparée. Mais il se produit quelque chose qui ressemble à une traduction… sans être une traduction.
On peut décrire le processus ainsi : votre phrase en français, arabe ou espagnol est tokenisée, puis transformée en vecteurs. À travers les couches internes, le modèle construit une représentation du sens et des relations. Et à la fin, il reprojette cette représentation en tokens de sortie dans la langue demandée.
Ce que certaines analyses suggèrent, c’est qu’au milieu du réseau, les représentations de différentes langues peuvent converger vers des schémas internes similaires, comme si le modèle trouvait une forme de représentation “commune”. Et quand la langue dominante de l’apprentissage est l’anglais, cette convergence peut naturellement prendre une teinte anglophone : non pas une traduction explicite, mais un alignement vers les structures les plus fréquentes et les plus stables.
C’est pour cela que l’on peut avoir une impression de “raisonnement en anglais” alors que l’utilisateur n’a jamais écrit un mot d’anglais : la sortie est bien en français, mais le trajet interne emprunte parfois des routes construites majoritairement en anglais.
De la théorie à la pratique : un exemple de ‘glissement’ linguistique
Sur le papier, tous les modèles se disent "multilingues". Mais à l'usage, la réalité est plus nuancée. Lors de nos tests avec Mistral — qui est pourtant l'un des modèles les mieux optimisés pour les langues européennes — on a observé un phénomène qui illustre parfaitement cet ancrage anglais : le décrochage linguistique sur la complexité.
Sur des questions simples, Mistral reste parfaitement fluide en français. Mais dès que le raisonnement devient très complexe ou demande une abstraction élevée, le modèle a parfois tendance à répondre en anglais, même si la consigne de langue est explicite dans le prompt. C’est un signe fréquent : pour “réfléchir” plus loin, le modèle se replie vers ses zones vectorielles les plus denses et les plus stables — souvent celles façonnées par l’anglais.
Face à cela, les modèles diffèrent surtout sur trois axes : leur capacité à rester stables dans la langue demandée, leur tolérance au raisonnement long sans “glissement”, et leur gestion de très grands contextes.
Le choix d'un modèle en entreprise ne doit donc pas se faire uniquement sur une évaluation générale, mais sur sa capacité à maintenir son raisonnement dans votre langue de travail sans "glisser" vers l'anglais dès que le sujet devient sérieux.
Conclusion : la langue n’est pas un détail, c’est un paramètre technique
Les LLM ne “pensent” pas avec des mots : ils manipulent des vecteurs. Et ces vecteurs sont façonnés par l’entraînement, donc par la distribution des langues vues pendant des milliards de tokens. Si l’anglais domine, il devient un ancrage naturel, parfois un pivot implicite, surtout quand la tâche devient difficile.
Ce constat n’est pas pessimiste. Au contraire : il ouvre une perspective très opérationnelle. Une organisation qui déploie des assistants IA multilingues doit considérer la langue comme une dimension de performance à part entière, au même titre que le contexte, le prompting, le RAG ou l’évaluation.
En clair : si votre IA semble plus intelligente en anglais, ce n’est pas une magie. C’est de la géographie interne. Et la bonne nouvelle, c’est que cette géographie peut se contourner, se compenser et, dans certains cas, se rééquilibrer.
Références:
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., ... & Amodei, D. (2020). Language Models are Few-Shot Learners. Papers with Code / arXiv:2005.14165. (Source pour le chiffre de 93 % concernant GPT-3).
OpenAI. (s.d.). Tokenizer. Consulté sur https://platform.openai.com/tokenizer. (Outil interactif permettant de visualiser la décomposition des mots en tokens selon les modèles GPT).
















