Machine learning pour l'estimation des coûts de projet : de la collecte à l’exploration
13min read • 2025-10-14 Data
Data
Data
Dans cet article, nous nous plongerons dans les deux premières étapes de machine learning présentées dans l’article précédent “Cycle de vie d’un projet de Machine Learning” avec un sujet incontournable de tout projet informatique : Cost Estimation ou bien l'estimation de la charge d’un projet, avec un focus sur les projets informatique.
Lorsque nous parlons de la charge d'un projet informatique, nous signifions le budget du projet « combien le projet va-t-il coûter ? » ainsi l'effort en hommes/mois ou en hommes/jours, en fonction de la taille du projet.
Nous allons vous montrer une toute nouvelle façon d'estimer la charge des projets informatiques. Au lieu d'utiliser des méthodes traditionnelles compliquées, nous avons opté pour quelque chose de beaucoup plus excitant.
Estimer la charge de projet en se basant sur l’historique des projets passés, et en utilisant des techniques d'apprentissage automatique pour prévoir les charges à venir.
Collecte de données
La première étape consiste à rassembler l'historique pertinent pour votre sujet, incluant tous les détails nécessaires, qu'ils soient qualitatifs ou quantitatifs.
Qui dit un projet Machine Learning, dit bien sûr une large quantité de données. En effet, les données sont la matière première qui nourrit le modèle d'apprentissage automatique. Sans un ensemble de données suffisant, on risque de ne pas aller très loin.
Il existe deux principales méthodes de collecte de données:
1. Collecte de données primaires
Consiste à collecter directement ces informations à partir de la source principale. Ce sont des informations qui n'ont jamais été exploitées auparavant. Ce sont des sources comme des enquêtes et des questionnaires, des expériences ou des observations. En général, ce genre de données est considéré comme le meilleur, même s'il est coûteux et demande du temps à obtenir.
2. Collecte de données secondaires
Désigne la collecte de données déjà collectées par une autre personne. Elles sont nettement plus abordables et plus simples à recueillir que les données initiales. Il est possible que ces informations proviennent de rapports, de bases de données, de publications ou d'autres sources ouvertes au public.
La richesse des données disponibles en ligne a rendu cette méthode de collecte de données secondaires extrêmement populaire. Des plateformes comme Kaggle, Hugging Face, UCI Machine Learning Repository ou Google Dataset proposent une multitude de jeux de données prêts à être téléchargés. Vous pouvez également utiliser le crawling et le scraping pour extraire des données à partir de sites web, réseaux sociaux ou articles.
Cependant, la meilleure alternative reste d’utiliser vos propres données, car rien de plus avantageux que de développer un modèle basé sur des données réelles et familières que vous maîtrisez. Assurez-vous simplement d'avoir suffisamment de données pour obtenir des résultats solides.
Dans notre article, nous avons opté pour une recherche en ligne de jeux de données cohérents avec les spécificités des projets informatique, ci-dessous les jeux de données les plus pertinents que nous avons retenu :
- ISBSG (International Software Benchmarking Standards Group) Une base de données internationale et indépendante de métriques de projets logiciels, regroupant des données recueillies auprès de différentes entreprises informatiques à travers le monde. Elle contient des métriques telles que les efforts de développement, les durées de projets, les tailles de projets, les technologies utilisées, les environnements de développement et les caractéristiques des équipes.
- SEERA (Software enginEERing in SudAn) est une collection de données spécifiques aux projets de génie logiciel réalisés au Soudan. Elle comprend des informations détaillées sur des projets de développement de logiciels, y compris les efforts de développement, les durées de projet, les tailles des équipes, les technologies utilisées, et d'autres métriques pertinentes.
- Cocomo81 (Constructive Cost Model 1981) est un modèle de coût de développement logiciel. Il se base sur des formules pratiques qui prennent en compte la taille des projets et d'autres facteurs pour estimer la quantité de travail requise
- PROMISE Software Engineering Repository : Un vaste dépôt de données provenant de nombreux projets de génie logiciel à travers le monde. Il offre une richesse d'informations sur les métriques de projet, les processus de développement, les caractéristiques des équipes et les technologies utilisées.
Ces jeux de données nous permettront d'explorer en profondeur les dynamiques de l’estimation de charge des projets informatiques et de développer des modèles prédictifs performants.
Exploration des données
La deuxième étape consiste à analyser les données et à les explorer en profondeur, une phase connue sous le nom d’EDA (Exploratory Data Analysis).
En transformant les données brutes en informations pratiques, vous pouvez découvrir des tendances et des insights précieux, ainsi que repérer et extraire les obstacles qui pourraient freiner la performance de votre modèle. Cette exploration est essentielle pour optimiser vos résultats et garantir le succès de votre modèle.
Exploration manuelle des données
Si vous êtes familiarisé avec vos propres données ou celles de votre organisation, vous pouvez explorer manuellement ces données en utilisant des bibliothèques populaires en Python telles que Pandas, Seaborn, Matplotlib, Plotly Express et d’autres.
Avant de plonger dans les détails techniques de l'exploration des données, assurez-vous que vous avez les configurations et les packages suivants installés. Voici les versions utilisées dans cet article :
- Python : 3.9.19
- Pandas : 2.2.1
- Seaborn : 0.12.2
- Matplotlib : 3.8.4
- Plotly : 5.20.0
- Pandas Bokeh : 3.4.0
- Pandas Profiling : 3.0.0
- Lux : 0.5.1
- Sweetviz : 2.3.1
1. Charger les données avec Pandas
La première étape consiste à charger nos données dans un DataFrame Pandas.
import pandas as pd
# Chargement des données
data = pd.read_csv('../data/Cocomo81.csv')2. Résumé statistique
Nous commençons par examiner les premières lignes, les types de données et les statistiques descriptives.
# Aperçu des premières lignes du dataset
data.head()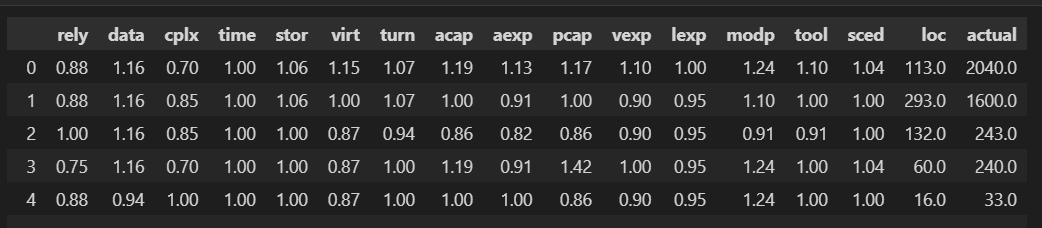
# Afficher les types de données
data.info()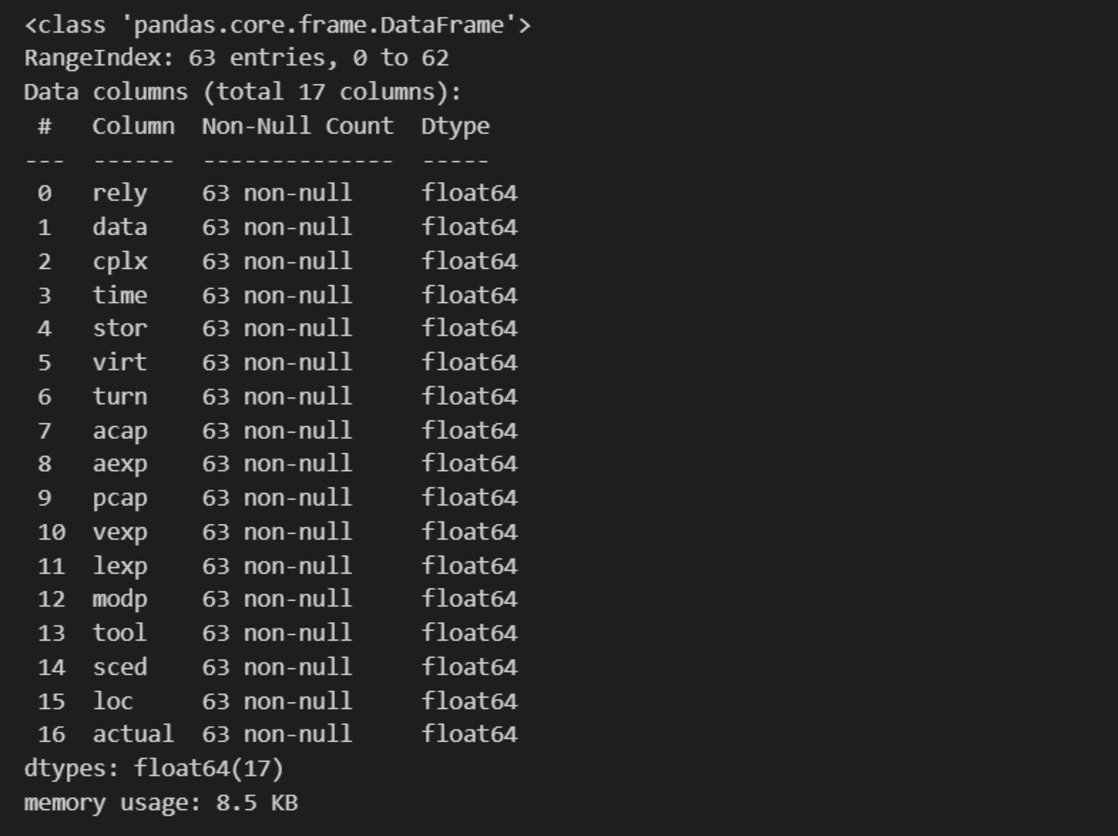
# Statistiques descriptives
data.describe()
3. Analyse bivariée avec Seaborn et Matplotlib
Nous utilisons ensuite Seaborn et Matplotlib pour créer des visualisations simples et découvrir des tendances dans les données.
import seaborn as sns
import matplotlib.pyplot as plt
# Graphique de dispersion entre LOC et Effort Réel
plt.figure(figsize=(10, 6))
sns.scatterplot(x='loc', y='actual', data=data)
plt.title('Lignes de Code vs Effort Réel')
plt.xlabel('Lignes de Code')
plt.ylabel('Effort Réel')
plt.show()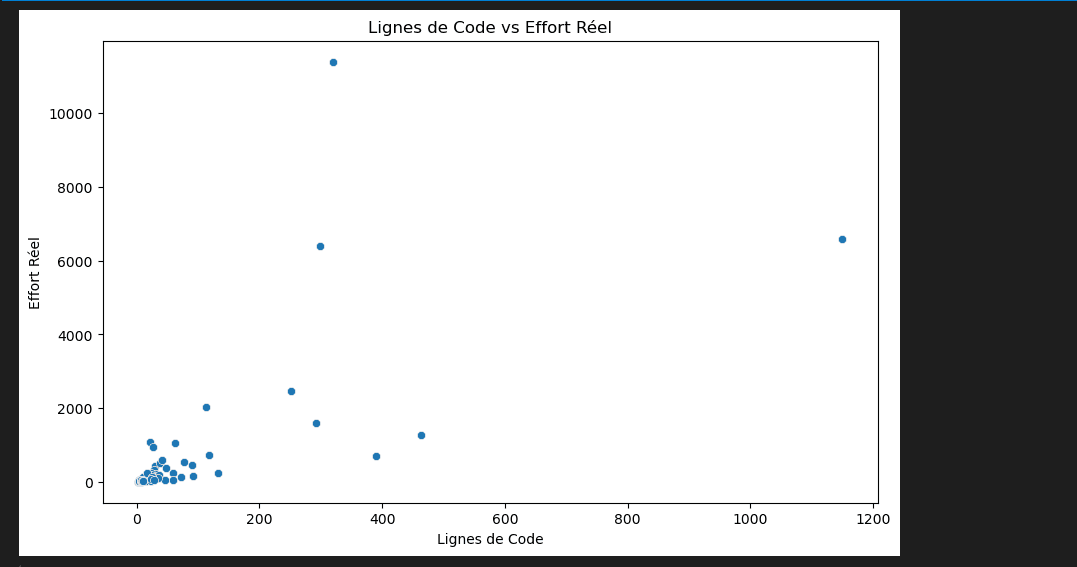
#afficher la corrélation des colonnes
colormap = plt.cm.viridis #Choix de la couleur
corr=data.corr()
plt.figure(figsize=(11,11))
sns.heatmap(corr,cmap=colormap,xticklabels=corr.columns,yticklabels=corr.columns,annot=True)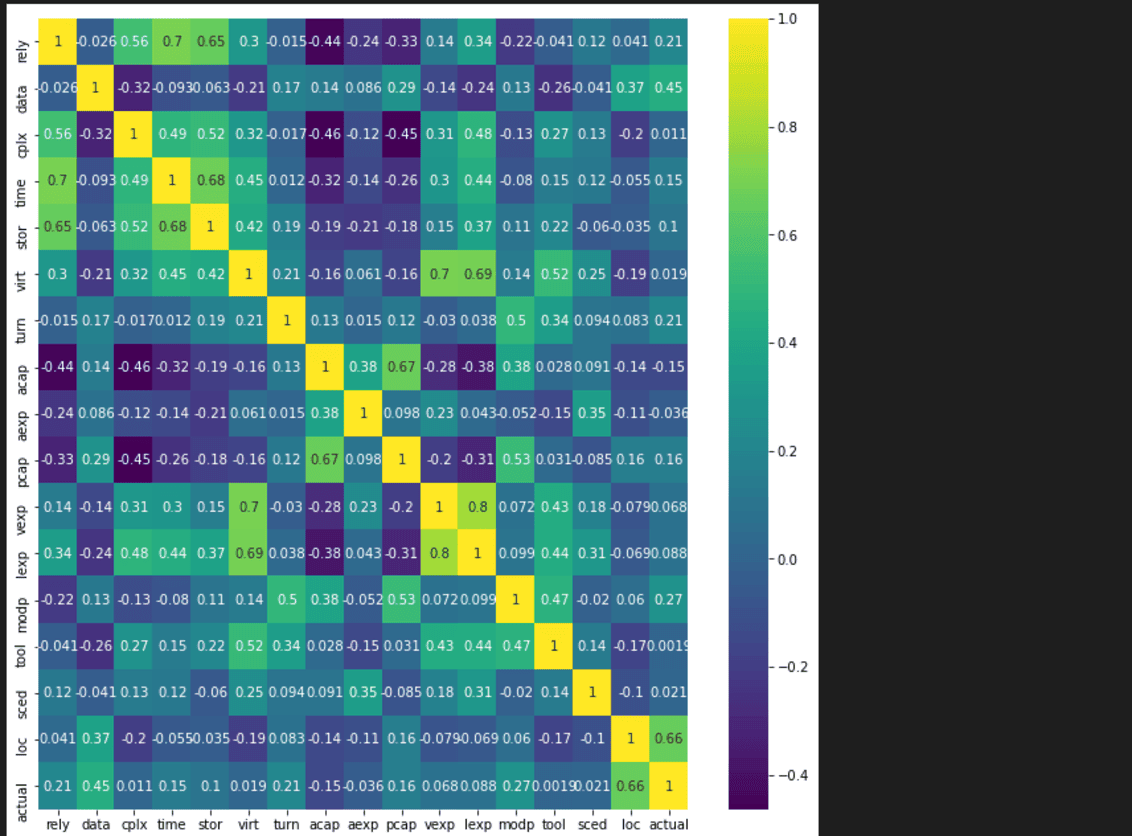
4. Visualisations interactives avec Plotly Express
Pour des visualisations interactives, vous pouvez utiliser Plotly Express ou Pandas Bokeh
Graphique de dispersion interactif avec Pandas_bokeh
import pandas_bokeh
pandas_bokeh.output_notebook()
data.plot_bokeh.scatter(x='loc', y='actual');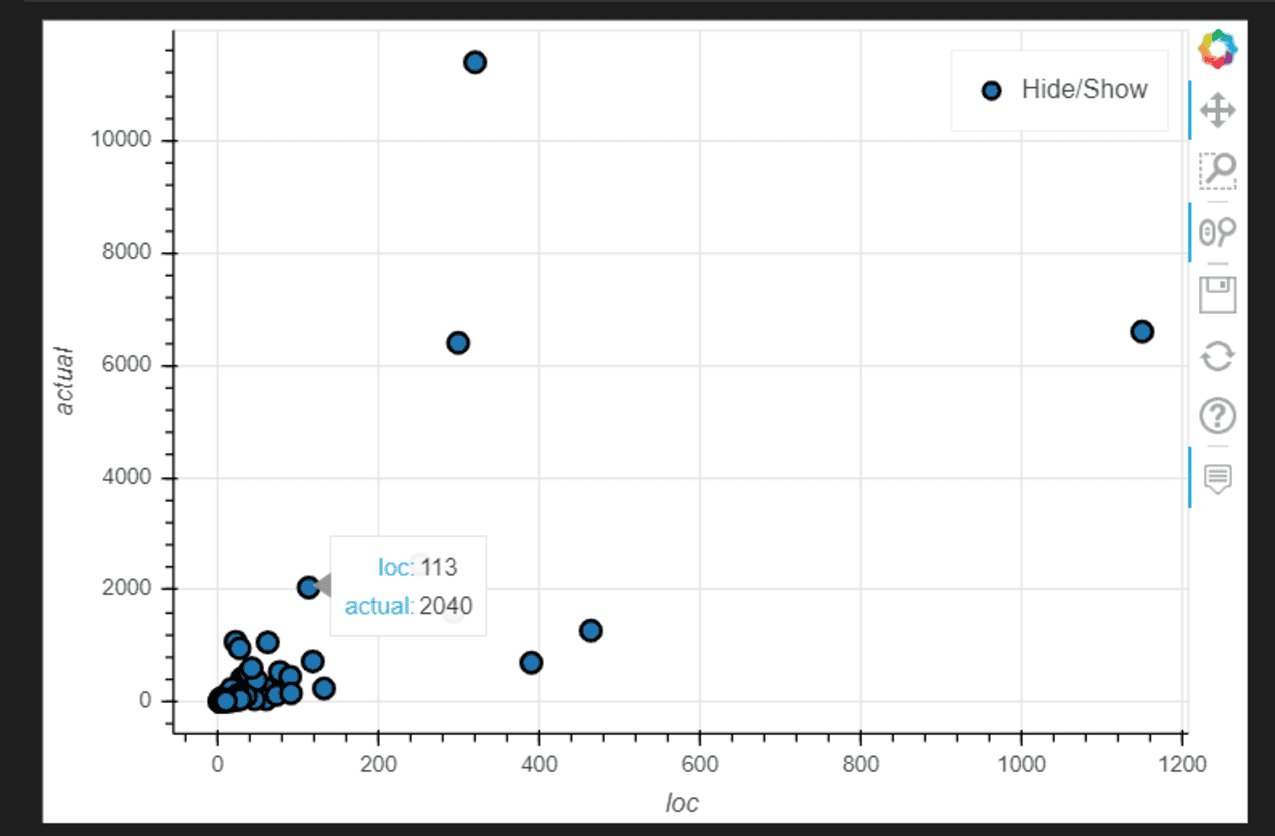
Le même visuel avec Plotly.express
import plotly.express as px
fig = px.scatter(df, x='loc', y='actual', color='rely',
title='Lignes de Code vs Effort Réel',
labels={'loc': 'Lignes de Code', 'actual': 'Effort Réel', 'RELY': 'Fiabilité'})
fig.show()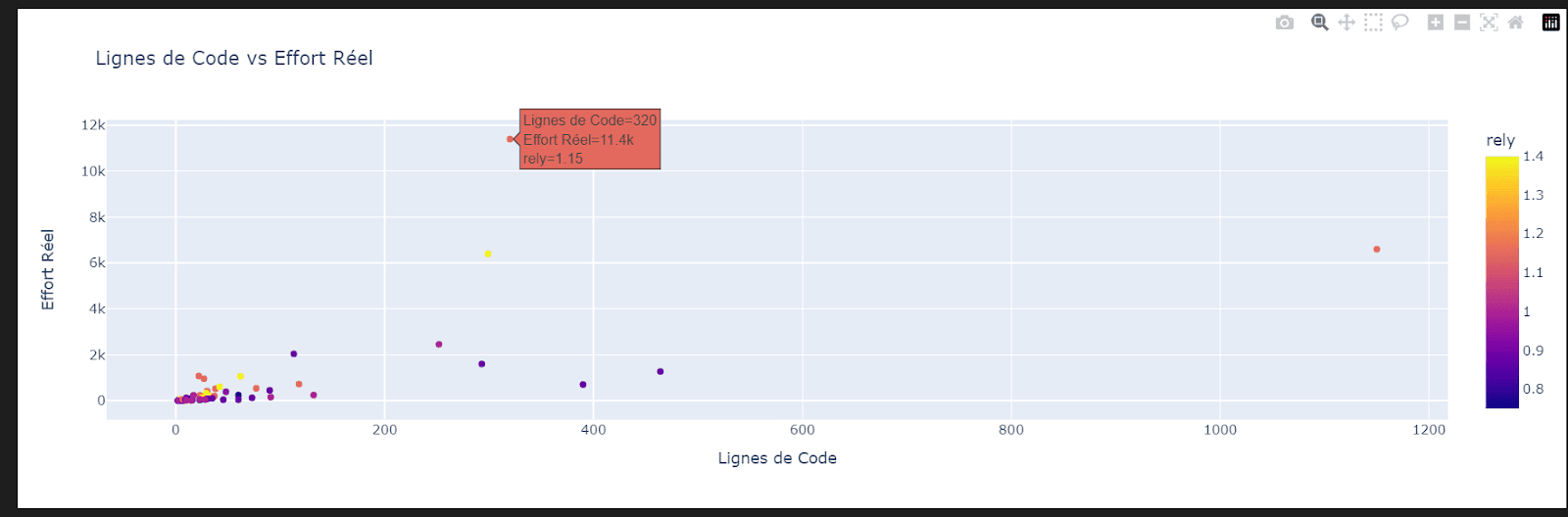
En suivant ces étapes, nous avons exploré manuellement le jeu de données Cocomo81. Cette exploration nous a permis de découvrir des tendances et des relations importantes, nous fournissant ainsi des insights précieux pour le développement de nos modèles prédictifs.
Exploration automatique des données
Si vous avez téléchargé des données à partir d'Internet et que vous ne savez pas par où commencer, il existe des solutions qui peuvent vous faire gagner du temps et vous aider à mieux comprendre les lacunes et les relations entre les différentes caractéristiques. Voici comment utiliser des outils de profilage automatique :
1. Pandas Profiling
Pandas Profiling permet de créer des rapports interactifs qui présentent un résumé statistique complet des données. Il offre une analyse approfondie incluant des statistiques descriptives, des distributions, des corrélations, et bien plus encore. Cela nous aide à identifier rapidement les caractéristiques importantes, les valeurs manquantes, et les anomalies dans les données.
import pandas as pd
from pandas_profiling import ProfileReport
data=pd.read_excel('../data/SEERA.xlsx')
# Générer le rapport
Report = ProfileReport(data, title='Pandas Profiling Report', explorative=True)
# Afficher le rapport
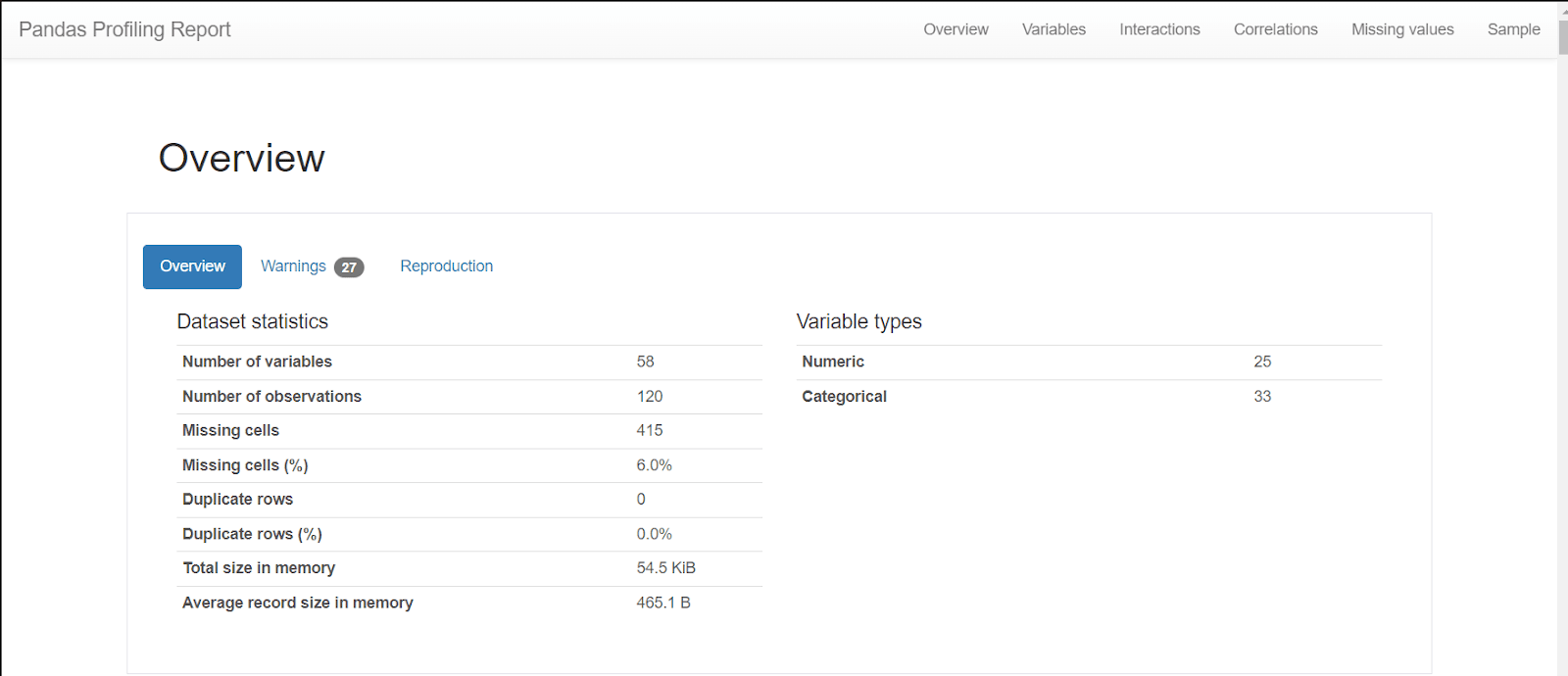
ReportUne fois le rapport généré, nous pouvons explorer les différentes sections. Le rapport inclut :
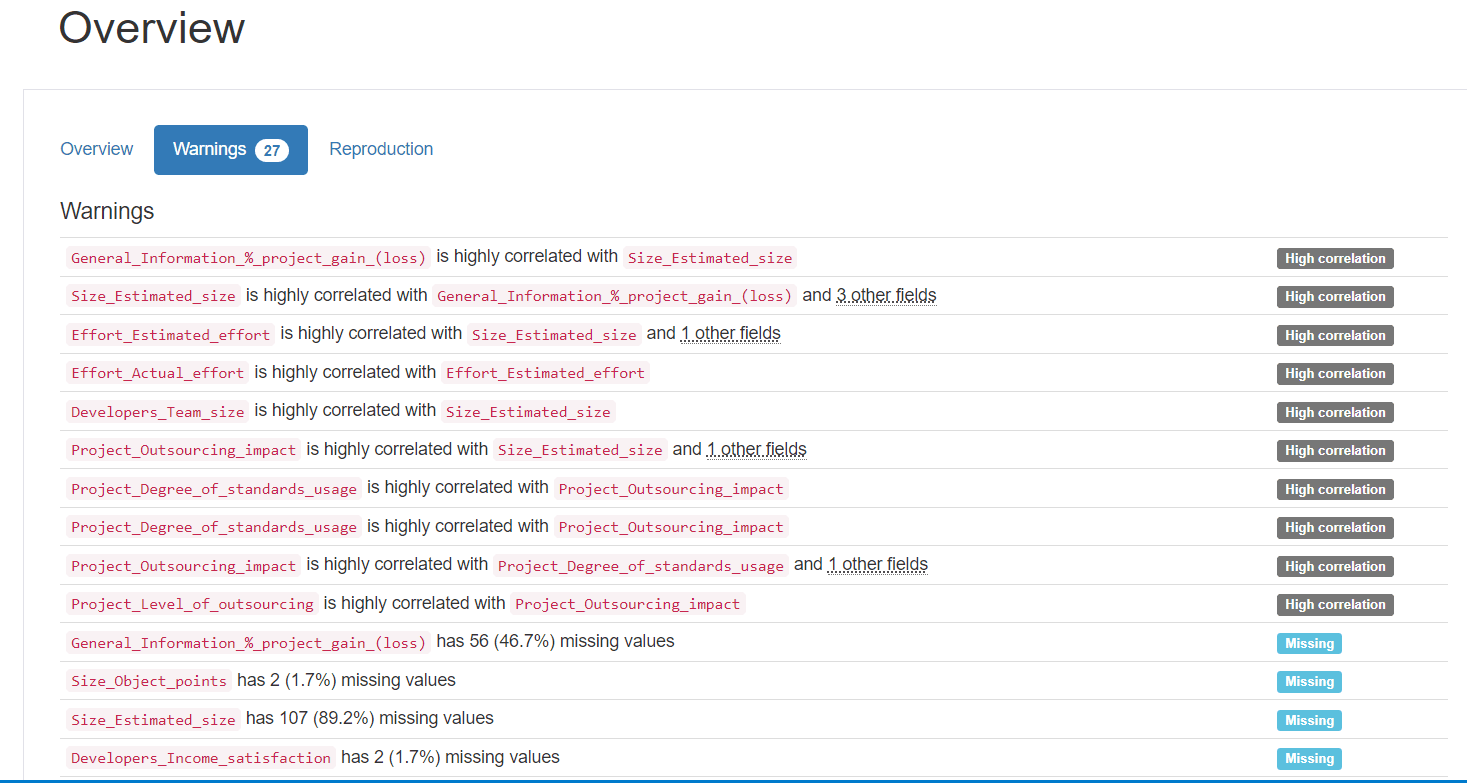
Overview : Une vue d'ensemble des statistiques clés comme le nombre de valeurs manquantes, les doublons, les types de données, la moyenne, la médiane, l'écart-type, etc..
warnings: Des indications sur les valeurs aberrantes, les valeurs manquantes, et d'autres anomalies potentielles.
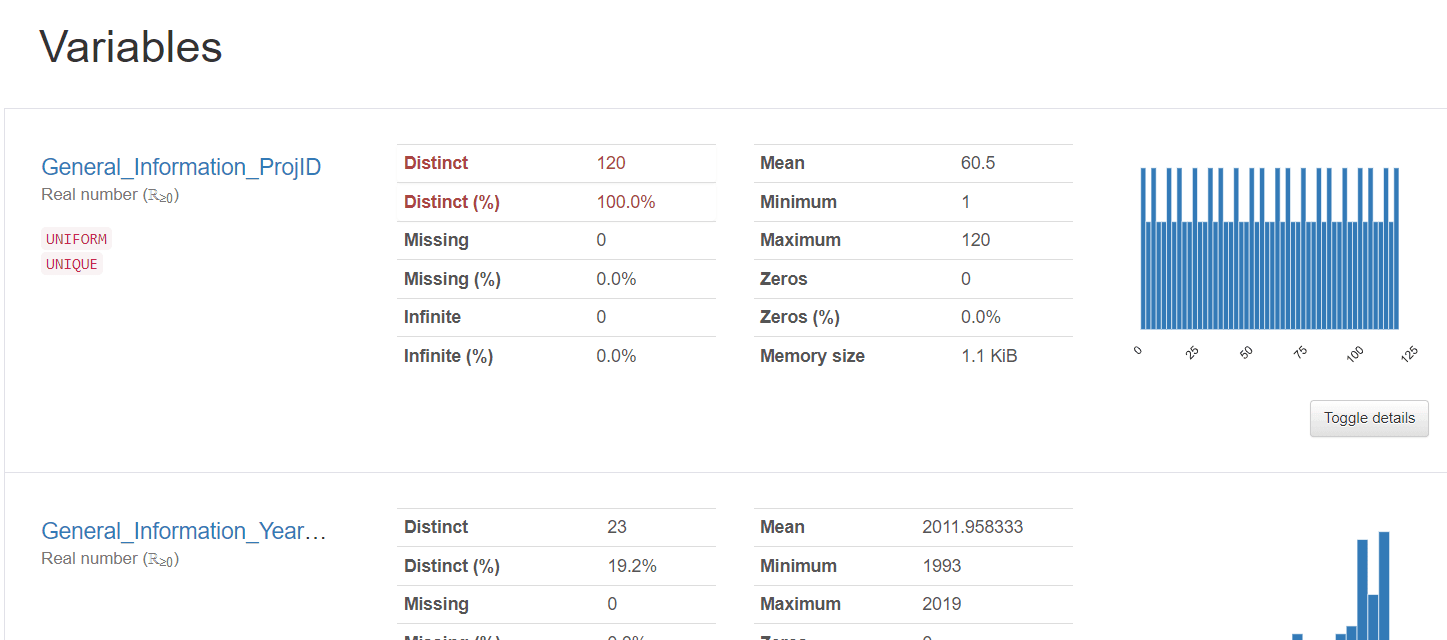
Variables: Des histogrammes montrant la distribution des données pour chaque colonne.
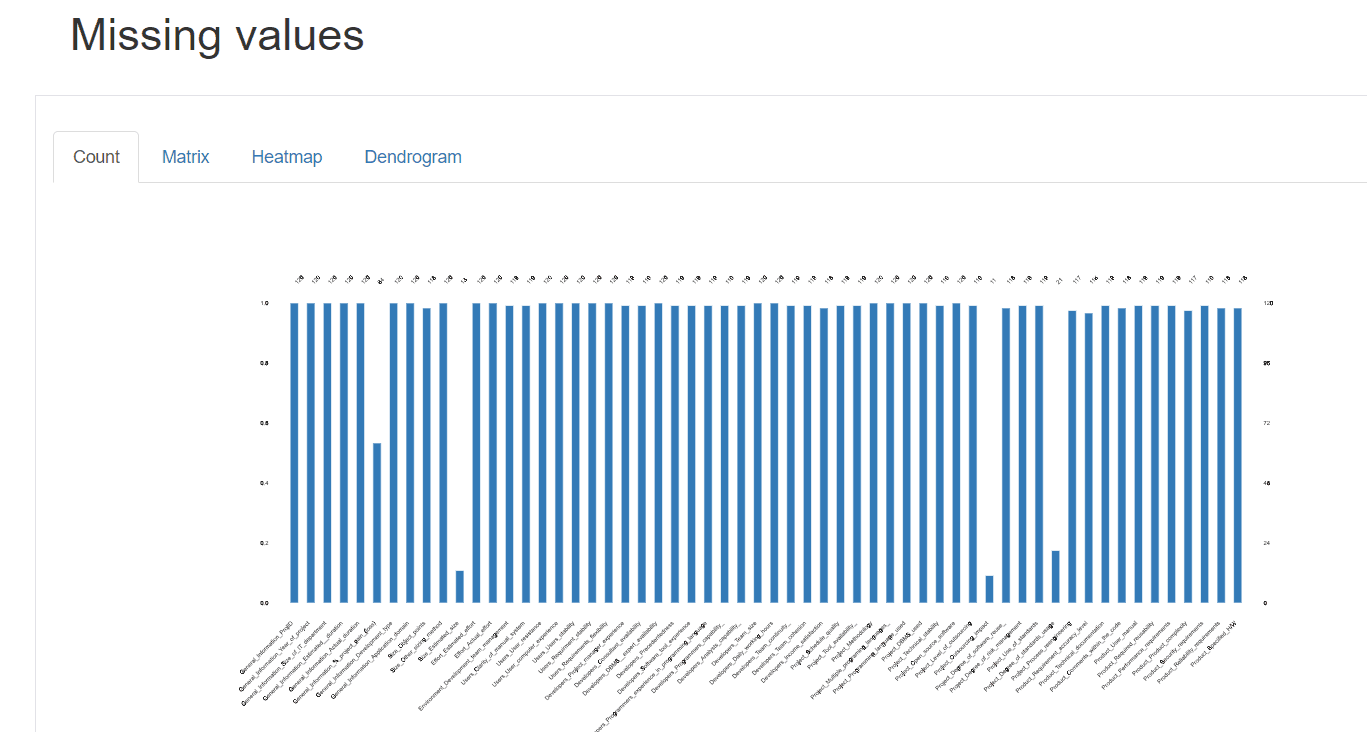
Missing values : Un visuel indiquant les valeurs manquantes pour chaque colonne, permettant d'identifier rapidement les colonnes qui nécessitent une attention particulière.
Correlations : Une matrice de corrélation indiquant les relations entre les différentes variables.

Avec Pandas Profiling, nous avons obtenu une analyse exhaustive de l'ensemble des données de SEERA en quelques minutes. Cela nous permet de gagner du temps et de mieux comprendre les données, ce qui est crucial pour le développement de modèles prédictifs performants.
2. Lux
Lux est une bibliothèque Python qui facilite l'exploration des données en générant automatiquement des visualisations pertinentes. Cela nous aide à découvrir des tendances, des relations et des anomalies dans nos données sans effort supplémentaire.
Pour bénéficier des visualisations automatiques générées par Lux, il suffit d'importer Lux puis Pandas. Ensuite, lorsque vous affichez votre DataFrame, un bouton Toggle Pandas/Lux apparaîtra pour afficher les visualisations
# import lux et pandas
import lux
import pandas as pd
#charger les données
df=pd.read_csv('../data/PROMISE-Data.csv')
#afficher le dataframe
df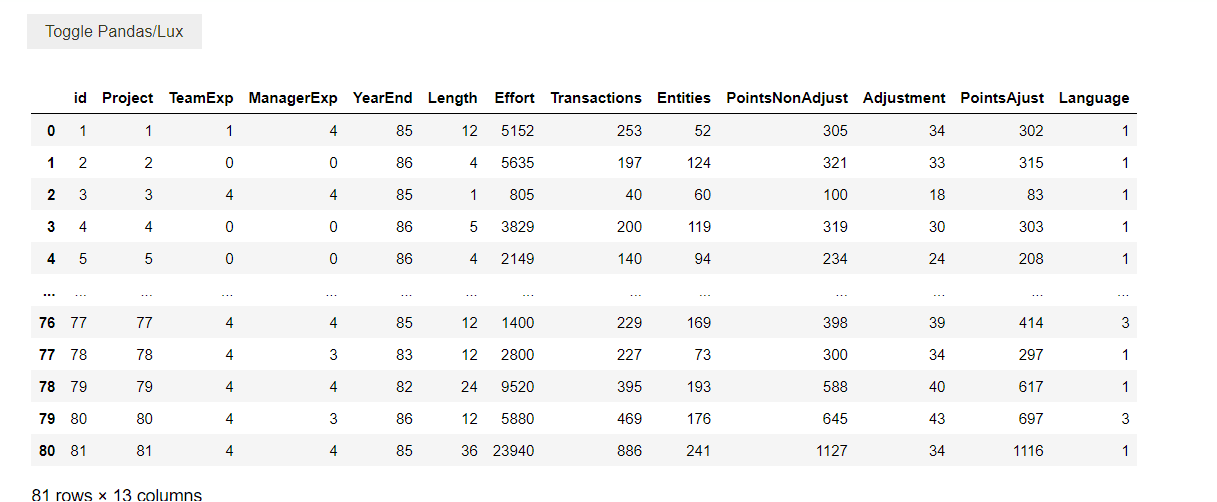
Exploration guidée
#spécifier un attribut
df.intent = ['Effort']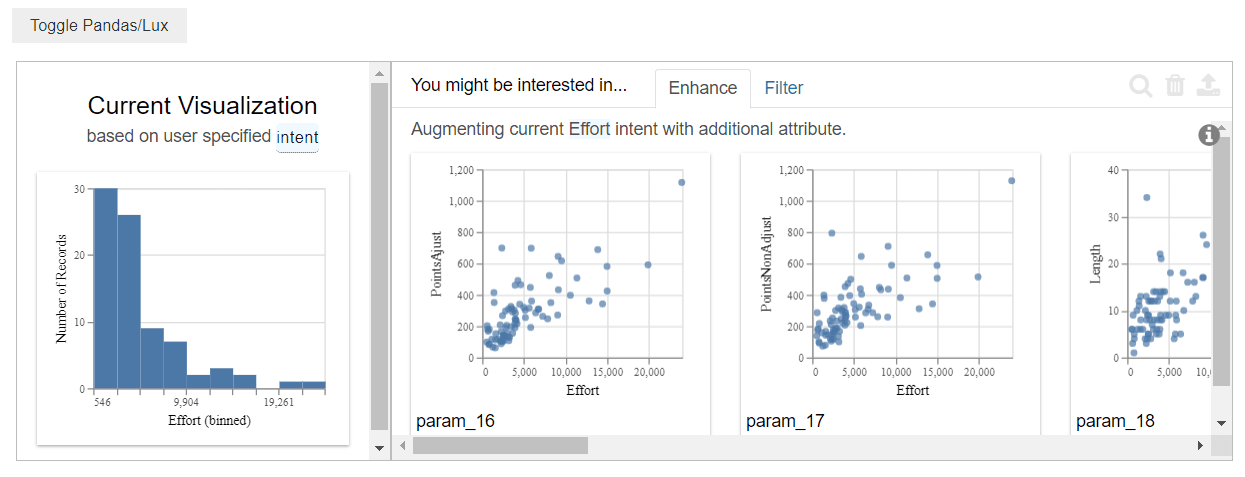
Lux propose une fonctionnalité d'exploration guidée qui simplifie l'analyse des données en spécifiant la variable d'intérêt. Dans notre cas, nous avons choisi l'effort de développement. Lux génère alors automatiquement les visualisations les plus pertinentes en fonction de cet objectif.
Une fois que nous avons défini notre objectif, Lux génère des visualisations et nous propose trois boutons interactifs pour affiner notre exploration :
- "Enhance" : Améliore les visualisations existantes en ajoutant plus de détails ou en modifiant les paramètres pour une analyse plus approfondie.
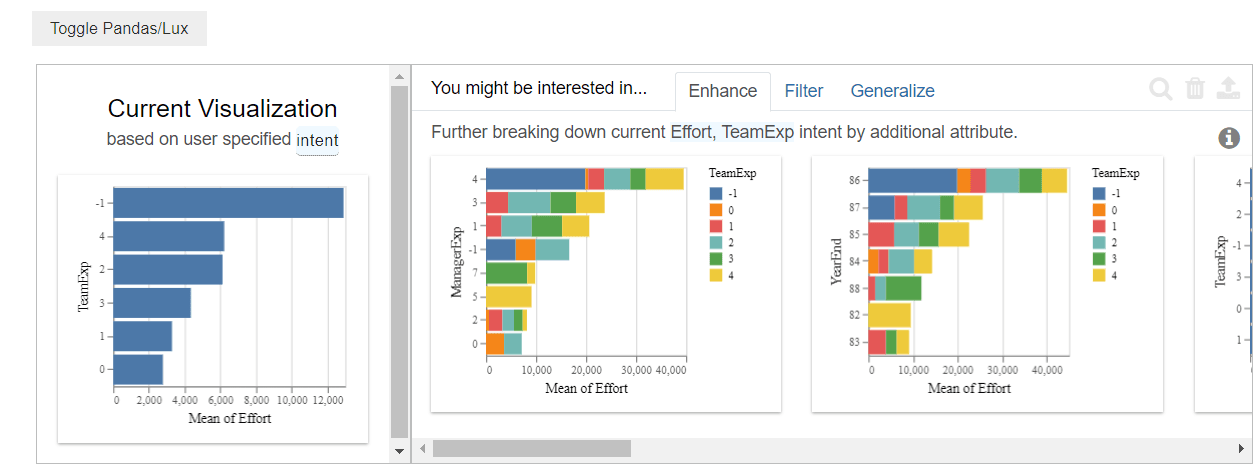
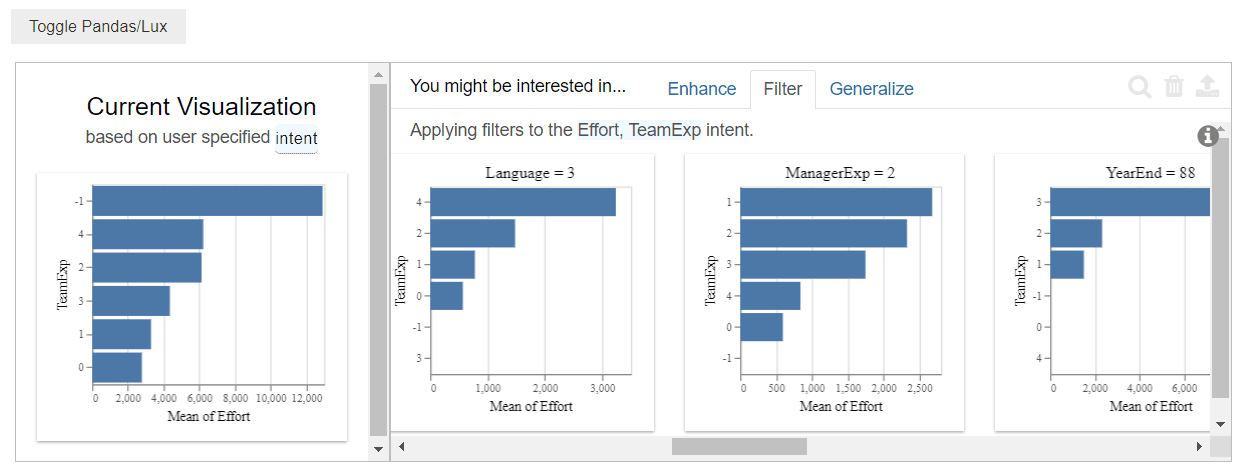
- Filter : Permet de filtrer les données affichées dans les visualisations pour se concentrer sur des sous-ensembles spécifiques ou des plages de valeurs particulières
- Generalize : Affiche des visualisations générales en considérant l'ensemble des données et leurs relations avec la variable d'intérêt.
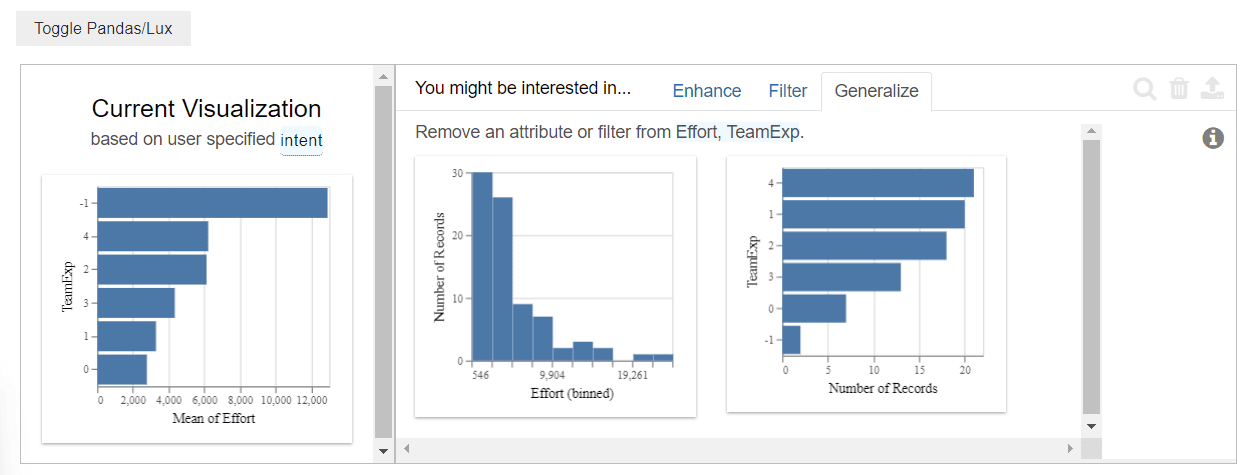
En utilisant cette fonctionnalité, Lux fournit des visualisations telles que des graphiques de dispersion montrant comment l'effort de développement est lié à d'autres variables. Ces visualisations nous aident à comprendre rapidement les facteurs qui influencent l'effort de développement dans l'ensemble de données PROMISE .
3. Sweetviz
Sweetviz est une bibliothèque Python qui facilite l'analyse exploratoire des données en générant des rapports visuels sous un fichier html. Cela nous aide à comprendre les caractéristiques de nos données, à identifier les valeurs manquantes et à repérer les anomalies.
import pandas as pd
import sweetviz as sv
#chargement de données dans un dataframe pandas
df=pd.read_excel("../data/ISBSG15.xls",header=(3))
#Analyser l'ensemble des données avec sweetviz
df_repo = sv.analyze(df)excel("../data/ISBSG15.xls",header=(3))Une fois le rapport généré, nous pouvons l'ouvrir dans un navigateur web pour explorer les différentes sections.
- Aperçu général : Une vue d'ensemble des statistiques clés comme la distribution des variables, les valeurs manquantes et les doublons. Des informations détaillées telles que la moyenne, la médiane, l'écart-type, etc., pour chaque colonne.
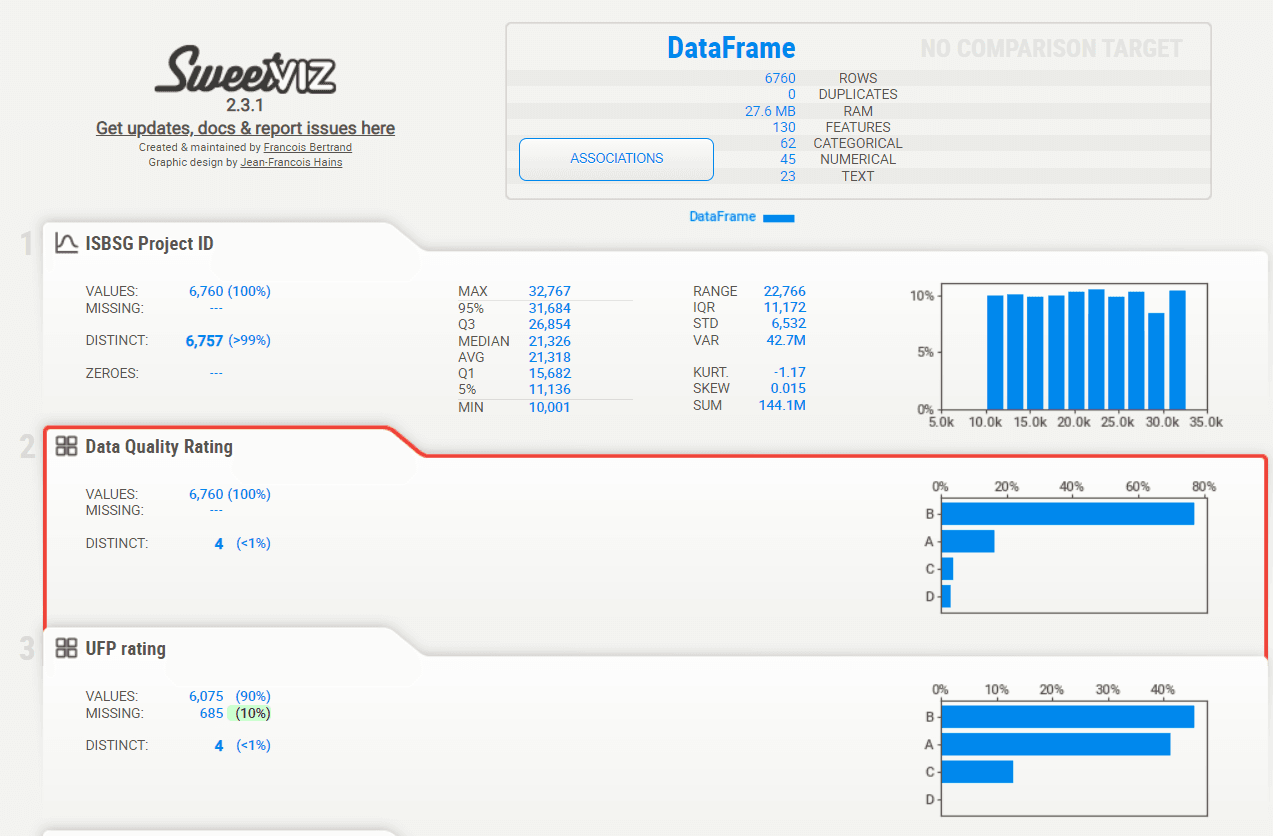
- Aperçu détaillé sur chaque colonne : En cliquant sur l'une des colonnes, une visualisation plus détaillée s'affiche, incluant des informations telles que la moyenne, la médiane, l'écart-type, et d'autres statistiques descriptives. Cette section permet d'examiner chaque variable en profondeur, de comprendre sa distribution, ses valeurs extrêmes, et ses anomalies.
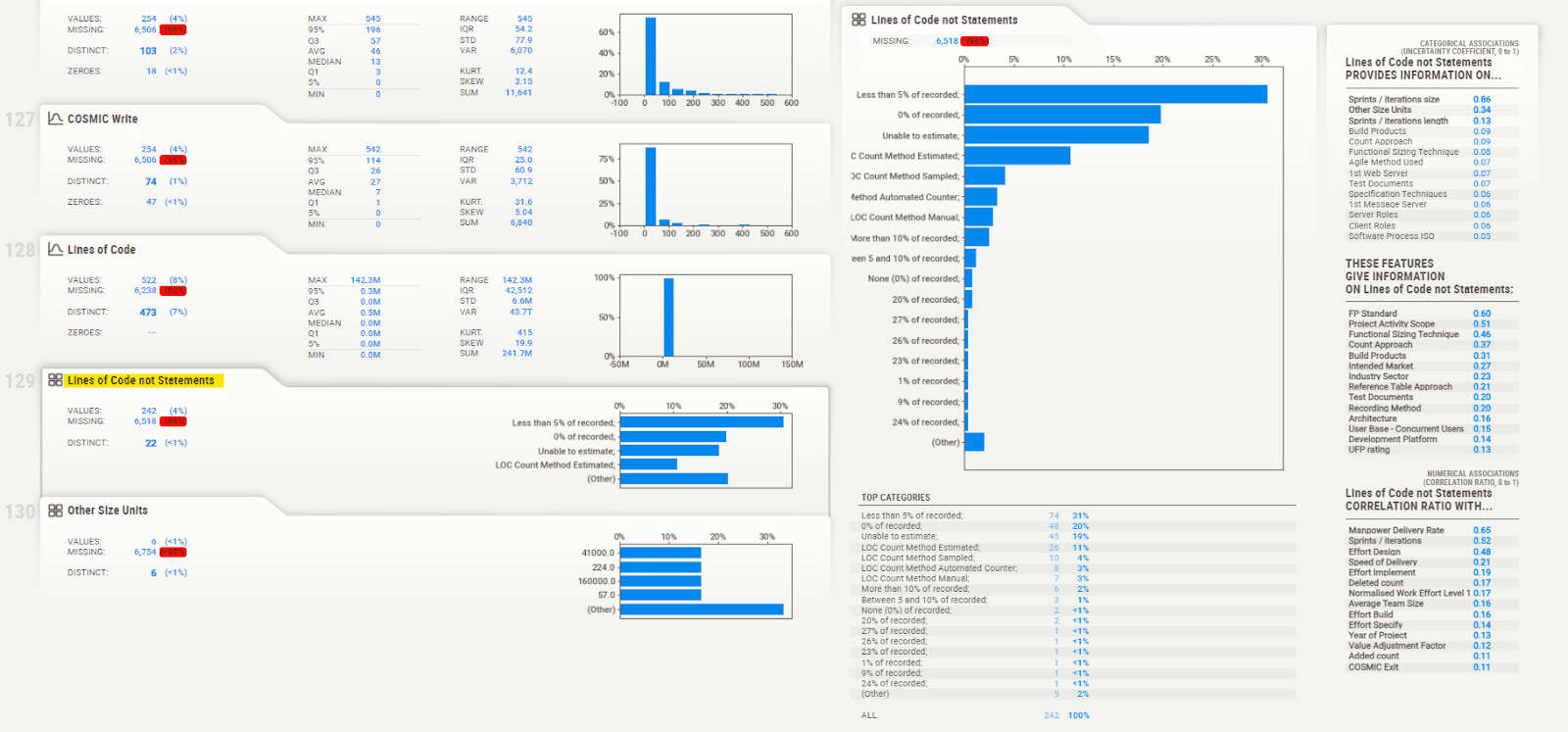
En utilisant Sweetviz, nous pouvons facilement naviguer dans les visualisations interactives, ce qui nous permet de découvrir rapidement des insights précieux et de mieux comprendre les dynamiques de l’ensemble de données ISBSG.
En suivant ces étapes, vous serez en mesure d'explorer vos données de manière manuelle et automatisée, en utilisant les bibliothèques Python les plus adaptées. Cette exploration est essentielle pour comprendre les dynamiques de vos données et préparer vos modèles prédictifs de manière optimale.
Conclusion et perspectives
Dans cet article, nous avons exploré les deux premières étapes essentielles du machine learning appliqué à l'estimation des coûts de projets informatiques : la collecte et l'exploration des données.
Nous avons présenté des méthodes de collecte de données primaires et secondaires, ainsi que l'exploration des données, réalisée à la fois manuellement et automatiquement à l’aide de bibliothèques Python. Cette étape nous a permis de transformer les données brutes en informations exploitables, essentielles pour le développement de modèles prédictifs fiables.
Dans les prochains articles, nous poursuivrons cette démarche en abordant les étapes suivantes du cycle de machine learning : préparation des données, sélection des modèles, entraînement, évaluation et interprétation des résultats, afin d’obtenir une vision complète et cohérente du processus d’estimation des coûts.
Bibliographie
https://www.kaggle.com/datasets
https://huggingface.co/datasets
https://plotly.com/python/plotly-express/
https://docs.bokeh.org/en/2.4.3/docs/user_guide/data.html
















