Ce que vos données cachent : l’art de découvrir l’invisible grâce à l’intelligence artificielle
12min read • 2025-12-29 Data
Data
Data
Pourquoi le non supervisé ?
Imaginez que vous entriez dans une immense pièce totalement sombre. Vous ne savez pas ce qui s’y trouve, et personne n’est là pour vous guider ou allumer la lumière. Pour comprendre l’espace, vous allez devoir avancer à tâtons, ressentir les formes, comparer les textures et regrouper mentalement les objets qui se ressemblent. Sans le savoir, vous faites un travail d'exploration pure.
C’est exactement ce que nous appelons l’apprentissage non supervisé.
Dans le monde idéal de l’intelligence artificielle, chaque donnée possèderait sa propre étiquette (par exemple : « ce client va partir », « cet achat est une fraude »). Mais dans la réalité du terrain, disposer de telles données est un luxe rare. Créer ces étiquettes à la main est un travail titanesque, coûteux et souvent sujet à l'erreur humaine.
La plupart du temps, les entreprises font face à une montagne de données "muettes" : massives, désordonnées et sans mode d'emploi.
C’est ici que l’approche non supervisée devient une alliée stratégique. Sa mission n’est pas de suivre des ordres précis ou de prédire un résultat connu d'avance, mais de révéler la structure cachée de vos activités. Elle agit comme un radar autonome capable de :
- Identifier des tendances émergentes dans des environnements en évolution rapide.
- Prioriser automatiquement les cas inhabituels pour réduire la charge d’analyse humaine.
- Détecter des signaux précoces de changement ou de risque latent.
En somme, le non supervisé agit comme un radar exploratoire: il aide à comprendre avant même de prédire, et à questionner avant d’affirmer.
Préparer des données réelles (et imparfaites)
Toute démarche non supervisée commence par un travail de fond sur la qualité et la cohérence des données.
Dans la réalité, les jeux de données sont rarement parfaits : doublons, valeurs manquantes, erreurs de saisie ou incohérences de format sont monnaie courante.
Avant tout apprentissage, il est essentiel de :
- Garantir la confidentialité et la conformité des données sensibles (anonymisation, masquage).
- Uniformiser formats, unités et types pour assurer la comparabilité.
- Nettoyer les doublons et gérer les valeurs manquantes pour limiter les biais.
- Préserver l’historique afin de comprendre les dynamiques d’évolution plutôt que de simples clichés statiques.
Un pipeline de données solide, traçable et cohérent constitue la base de toute modélisation pertinente. Sans cette fondation, le modèle risque d’apprendre les artefacts techniques plutôt que la logique réelle des phénomènes observés.
Créer des variables porteuses de sens
Les algorithmes non supervisés n’ont aucune connaissance du contexte métier : c’est au data scientist de construire ce sens.
Le feature engineering devient alors une étape clé : il s’agit de construire des indicateurs qui traduisent le comportement, la relation ou l’évolution des entités observées.
Exemples courants :
- Des mesures de fréquence (nombre d’événements, régularité, répétitions).
- Des ratios ou écarts proportionnels (coûts relatifs, taux de variation).
- Des variables temporelles (délai entre événements, saisonnalité, tendance).
Une fois les variables définies, on applique des techniques d’encodage et de mise à l’échelle adaptées à leur nature pour éviter qu’une seule dimension ne domine le calcul. Enfin, des méthodes comme la PCA (Analyse en Composantes Principales, voir article complet) condensent l’information dans un espace plus compact et interprétable tout en réduisant le bruit.
Les grandes familles de modèles non supervisés
L’apprentissage non supervisé n’est pas une méthode unique, mais un écosystème d’approches.
Chaque algorithme incarne une vision différente de ce qu’est une “anomalie” ou une “structure” dans les données.
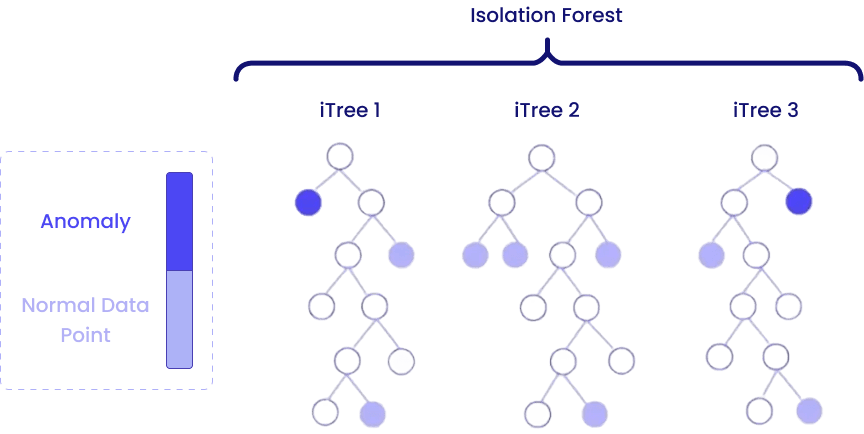
Isolation Forest — détecter par séparation aléatoire
Intuition :
Les anomalies sont rares et différentes; il faut donc moins de décisions pour les isoler que pour les points normaux.
Isolation Forest exploite cette idée simple : il crée de nombreux arbres de décision aléatoires et observe combien de coupures (ou « splits ») sont nécessaires pour isoler chaque observation.
Mécanisme :
- On choisit aléatoirement une variable, puis un seuil pour la diviser.
- On répète cette opération pour construire un grand nombre d’arbres.
- Chaque observation parcourt ces arbres jusqu’à être isolée: plus le chemin est court, plus le point est considéré comme atypique.
Pourquoi ça marche :
Un point rare est souvent « seul » dans une région de l’espace : il sera donc séparé du reste dès les premières divisions.
Les points normaux, eux, nécessitent plus de divisions car ils se trouvent dans des zones denses.
Forces :
- Très rapide (même sur des millions de lignes).
- Peu de paramètres à régler.
- Gère bien les données de haute dimension.
Limites :
- Moins adapté si les anomalies se trouvent au sein de zones denses.
- L’aléatoire nécessite plusieurs exécutions pour stabiliser les résultats.
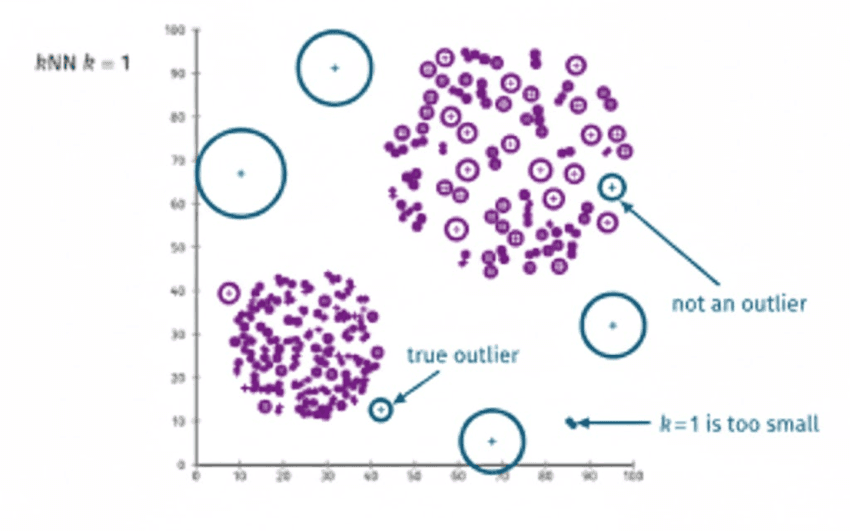
Local Outlier Factor (LOF) — détecter par densité locale
Intuition :
Une observation peut paraître normale à l’échelle globale, mais être isolée dans son voisinage immédiat.
Le LOF mesure donc la densité locale autour d’un point et la compare à celle de ses voisins.Mécanisme :
- Pour chaque point, on calcule la distance jusqu’à ses k plus proches voisins.
- On en déduit sa densité locale (l’inverse de la distance moyenne aux voisins).
- Un point dont la densité est significativement inférieure à celle de ses voisins reçoit un score d’anomalie élevé.
Pourquoi c’est puissant :
LOF identifie des anomalies contextuelles: un point peut être rare uniquement dans une région donnée du jeu de données, sans l’être globalement.
Exemple : un salarié avec un salaire normal à Paris mais très élevé dans une petite ville — LOF le détectera.Forces :
- Capte les anomalies locales invisibles aux modèles globaux.
- On ne suppose aucune forme particulière de la distribution.
Limites :
- Le choix du paramètre k est crucial.
- Sa complexité de calcul limite son usage sur de très grands volumes.
K-Means et ses dérivés — détecter par distance au centre
Intuition :
Les individus semblables forment naturellement des groupes (« clusters »). Les points éloignés du centre de tout cluster peuvent être considérés comme atypiques.
Mécanisme :
- L’algorithme regroupe les données en k clusters de manière à minimiser la distance intra-groupe.
- Chaque observation est assignée à son centroïde le plus proche.
- Plus la distance au centroïde est grande, plus la probabilité d’anomalie augmente.
Extensions utiles :
- DBSCAN (et sa variante HDBSCAN) ne demandent pas de définir k et détectent les anomalies comme points non rattachés à un cluster dense.
- Ces méthodes sont idéales quand les clusters ne sont pas sphériques ou équilibrés.
Forces :
- Très interprétable.
- Rapide sur des données bien normalisées.
Limites :
- Nécessite un prétraitement (mise à l’échelle).
- Suppose que les clusters sont de forme simple et de taille comparable.
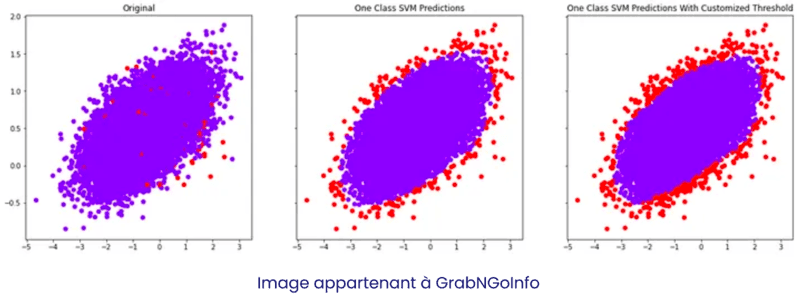
One-Class SVM — détecter par frontière
Intuition :
Plutôt que de chercher à isoler les anomalies, on cherche à délimiter la zone normale.
Le One-Class SVM apprend une frontière qui englobe la majorité des données : tout ce qui se situe à l’extérieur est considéré comme anormal.
Mécanisme :
- Le modèle projette les données dans un espace de grande dimension via un noyau (kernel).
- Il construit une frontière (une hypersurface) qui sépare la zone dense du reste.
- Les points situés au-delà de cette frontière sont marqués comme anomalies.
Forces :
- Modélise des frontières complexes, non linéaires.
- Fonctionne bien sur des données propres et de taille moyenne.
Limites :
- Très sensible aux paramètres (nu, gamma).
- Mauvaise évolutivité sur les grands volumes.
- Moins interprétable que les approches basées sur la densité.
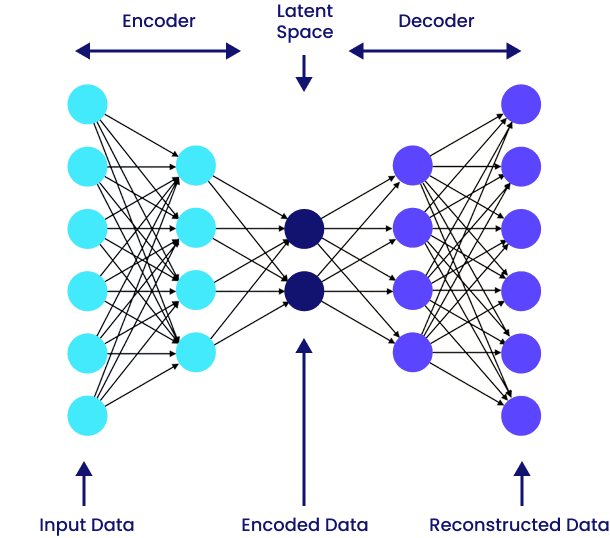
Autoencodeur — détecter par reconstruction
Intuition :
Un système bien entraîné sur les comportements “normaux” apprend à les reproduire fidèlement. Lorsqu’il rencontre quelque chose d’inhabituel, il échoue à le reconstruire: l’erreur de reconstruction devient un signal d’anomalie (voir article complet).
Mécanisme :
- Un encodeur compresse les données dans un espace latent réduit.
- Un décodeur tente de reconstruire les données initiales.
- La différence entre entrée et sortie (la reconstruction error) sert d’indicateur d’anomalie.
Variantes :
- Variational Autoencoder (VAE) : introduit une dimension probabiliste (on apprend une distribution plutôt qu’un point latent).
- LSTM Autoencoder : conçu pour les séries temporelles.
- Convolutional Autoencoder (CAE) : adapté aux images et signaux spatiaux.
Forces :
- Gère les structures non linéaires et les dépendances complexes.
- Adaptable à presque tout type de données.
Limites :
- Besoin de beaucoup de données « normales ».
- Risque de surapprentissage (reconstruire même les anomalies).
- Peu interprétable sans visualisation ou analyse des activations.
Évaluer sans labels
L’absence de vérité terrain rend l’évaluation du non supervisé délicate: comment savoir si les anomalies détectées sont “bonnes” si personne ne les a validées ?
On se base alors sur des indicateurs internes, des mesures de cohérence et, parfois, un consensus entre modèles.
Mesures internes de structure
Ces métriques servent à juger la qualité du clustering produit par le modèle — autrement dit, à vérifier s’il a su dégager une organisation logique des données.
Silhouette Score
Cet indicateur évalue la cohésion d’un cluster et sa séparation vis-à-vis des autres. Un score proche de 1 signifie que les individus sont bien rassemblés autour de leur centre et clairement distincts des autres groupes. Il est particulièrement utile pour choisir le bon nombre de clusters ou comparer différents algorithmes de regroupement.
Davies–Bouldin Index
Il mesure le compromis entre compacité interne et séparation externe. Plus l’indice est faible, plus les clusters sont nets et peu chevauchants. Il permet de détecter les partitions floues où des groupes se recouvrent partiellement.
Calinski–Harabasz Score
Cette métrique examine le rapport entre la dispersion inter-clusters et intra-clusters. Un score élevé indique des groupes denses, bien distincts les uns des autres. C’est une mesure synthétique, efficace pour valider la structure globale du modèle.
Ces métriques donnent une idée de la qualité du regroupement, mais ne disent rien sur les anomalies elles-mêmes.
Mesures spécifiques à la détection d’anomalies
Une fois la structure validée, on s’intéresse aux observations qui s’en écartent. Chaque famille de modèles produit son propre indicateur d’« éloignement à la norme ».
Erreur de reconstruction (Autoencodeurs)
Elle compare les données originales à leur reconstruction. Un écart élevé traduit un comportement que le modèle n’a pas appris à reproduire — un signal d’anomalie fort. C’est une mesure intuitive: plus le système échoue à reconstituer une donnée, plus celle-ci est singulière.
Score d’isolation (Isolation Forest)
Il reflète la facilité avec laquelle un point peut être isolé des autres. Les observations rares, séparées rapidement par les arbres du modèle, obtiennent des scores proches de 1. Ce score capture bien les comportements extrêmes ou rares.
Score de densité (LOF, DBSCAN, HDBSCAN)
Ici, la rareté est perçue à travers la densité locale. Un individu entouré de peu de voisins similaires reçoit un score d’anomalie élevé. Cette approche détecte efficacement les irrégularités « contextuelles » — celles qui ne sont pas extrêmes globalement, mais décalées dans leur voisinage.
Probabilité d’appartenance (GMM, VAE)
Les modèles probabilistes estiment la vraisemblance d’une observation au regard de la distribution globale. Les points à faible probabilité sont considérés comme atypiques. C’est une approche plus statistique, utile quand on cherche une interprétation quantitative de la rareté.
Approches de consensus et robustesse
Aucune méthode n’offre une vision complète du phénomène. Chaque algorithme capture une facette différente de la « normalité ». Pour renforcer la fiabilité, on combine plusieurs modèles et on observe leur niveau d’accord.
Apprentissage non supervisé par ensemble
On exécute plusieurs détecteurs (ex. : Isolation Forest, LOF, Autoencodeur, GMM), puis on agrège leurs scores. Les observations signalées par plusieurs méthodes sont considérées comme plus fiables : le consensus agit comme un filtre qui réduit les faux positifs.
Mesures d’accord
Pour quantifier ce consensus, on utilise :
- L’indice de Jaccard, qui mesure la proportion d’anomalies communes entre modèles.
- Le Rand ajusté, qui compare deux partitions du jeu de données.
- Le coefficient de Cohen’s Kappa, qui évalue si la concordance dépasse le hasard.
Un fort accord entre modèles indépendants indique un signal robuste, c’est-à-dire une anomalie structurelle et non un simple artefact algorithmique.
Boucles de validation et retour expert
Enfin, le non supervisé gagne en précision lorsqu’il s’intègre dans une boucle d’apprentissage :
- Les anomalies détectées sont revues par des experts humains.
- Les cas confirmés servent ensuite à affiner les modèles ou à entraîner un futur modèle supervisé.
Ce cycle data → modèle → validation → réapprentissage transforme le non supervisé en véritable outil d’apprentissage continu.
En perspective
L’apprentissage non supervisé est avant tout un outil d’exploration intelligente.
Sa force ne réside pas dans la complexité des algorithmes, mais dans la rigueur du pipeline et la pertinence de l’interprétation. Il permet de comprendre avant de prédire, de détecter avant d’expliquer, et d’orienter l’expertise humaine là où elle apporte le plus de valeur.
Dans des domaines sensibles comme la santé, il devient un allié stratégique pour renforcer la vigilance, fiabiliser les processus et nourrir une culture data fondée sur la découverte et l’amélioration continue.
















