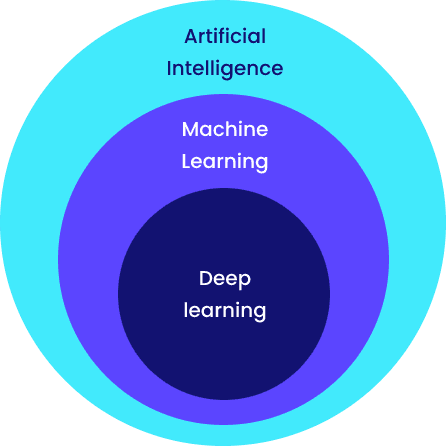
IA, Machine Learning et Deep Learning : Concepts et plateformes
7min read • 2022-03-16 Data
Data
Data
L’intelligence artificielle, Machine Learning et Deep Learning sont des concepts de plus en plus populaires, et ce depuis quelques années. Dans cet article, nous allons définir chacun de ces concepts et expliquer quelles différences existent entre eux.
Tout a commencé dans les années 1950, lorsque le mathématicien Alan Turing se posait une question : “Les machines peuvent-elles penser ?”. Cette simple question allait changer le monde.
En effet, l’intelligence artificielle (IA) vise à répondre à la question d’Alan Turing de manière affirmative. Son objectif est de construire des machines capables de faire tout ce qu’un humain peut faire, ou même d’être une super-intelligence et de faire plus de choses qu’un simple être humain. En bref, l’intelligence artificielle est l’intelligence humaine manifestée par des machines.
L’intelligence artificielle désigne aussi toute technologie qui semble faire quelque chose d’intelligent, ou qui reproduit le comportement humain. Il peut s’agir d’un logiciel programmé ou de modèles d’apprentissage profond qui simulent l’intelligence humaine.
Machine Learning ou l’apprentissage automatique est un domaine de l’intelligence artificielle qui consiste à programmer une machine grâce à une catégorie d’algorithmes pour qu’elle apprenne à effectuer des tâches sans être explicitement programmée, en étudiant des exemples. Le principe de base de l’apprentissage automatique est de construire des modèles qui peuvent recevoir des données en entrée et utiliser une analyse statistique pour prédire une sortie.
Deep Learning : Il s’agit d’un sous-ensemble de l’apprentissage automatique basé sur le modèle de réseau de neurones inspiré du cerveau humain.
Machine Learning : Apprentissage supervisé et non supervisé
On distingue différents types d’algorithmes d’apprentissage automatique, ces algorithmes peuvent être divisés d’une manière générale en deux catégories : supervisés et non supervisés.
Apprentissage supervisé : consiste à superviser l’apprentissage de la machine en montrant à celle-ci des exemples (des données) de la tâche qu’elle doit réaliser. Par exemple, la machine peut apprendre à reconnaître une photo de chat après avoir vu des millions de photos de chats. Ou encore, elle peut apprendre à traduire le français en anglais après avoir vu des millions d’exemples de traduction français-anglais.
D’une manière générale, l’objectif est de trouver une fonction (f) qui décrit au mieux les données d’entrée (x) pour déduire les données de sortie (y). Nous connaissons x et nous connaissons y, mais nous devons trouver la fonction de correspondance (f). Ensuite, nous pouvons appliquer la fonction de mise en correspondance (f) aux nouvelles données pour obtenir des résultats similaires.
y = F(x)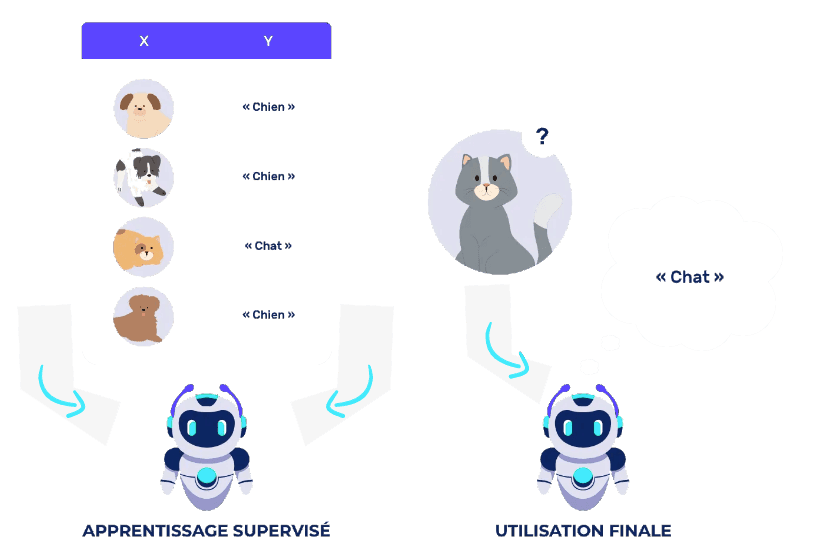
Il existe deux types de problèmes d’apprentissage automatique supervisé :
- Classification : On parle de problème de classification lorsque la variable de sortie est une catégorie, exemple si je veux déterminer quel animal sur une photo.
- Régression : Un problème de régression se pose lorsque la variable de sortie est un nombre, exemple si je vous prédire le taux de risque associé à une opération.
Apprentissage non supervisé : Contrairement à l’apprentissage supervisé, l’apprentissage non supervisé est utilisé lorsque le jeu de données en entrée ne contient pas d’exemples indiquant ce qu’on recherche, l’algorithme utilise des données non étiquetées. On dispose donc d’un ensemble de données x sans variable y, et la machine apprend à reconnaître les structures dans les données x qu’on lui montre. En effet, l’apprentissage par la machine se fait de manière entièrement indépendante.
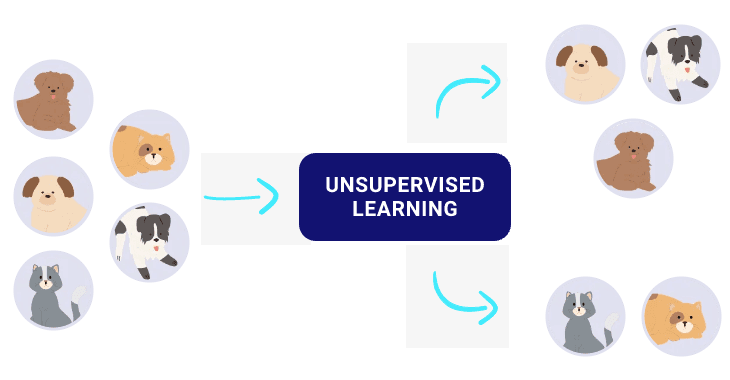
L’utilisation de l’apprentissage non supervisé peut être réunie en problèmes de clustering et d’association.
- Clustering : Un problème de regroupement consiste à découvrir les regroupements inhérents aux données, par exemple en regroupant les clients par comportement d’achat.
- Association : Une règle d’association est une méthode qui sert à trouver des relations entre des variables dans un ensemble de données défini. Par exemple, ces méthodes permettent aux entreprises de mieux comprendre les habitudes de consommation des clients pour développer de meilleures stratégies de vente.
Deep Learning : Réseaux de neurones
Le Deep Learning est un domaine de machine learning basé sur les réseaux de neurones artificiels. C’est un réseau de fonctions de type f(x) = ax+b connectées les unes aux autres.
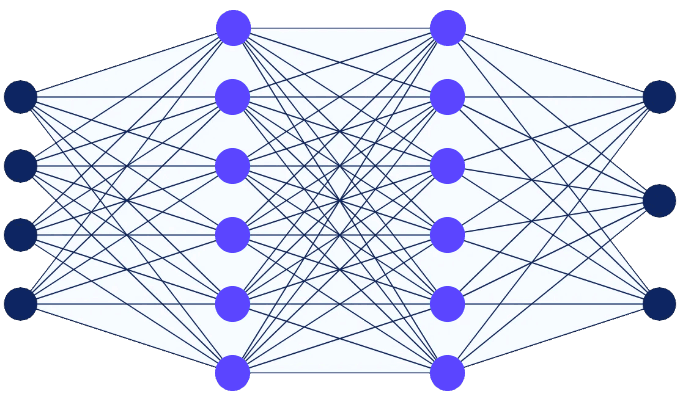
Plus ces réseaux sont profonds, c’est à dire plus ils contiennent de fonctions à l’intérieur, plus la machine est capable d’apprendre à réaliser des tâches complexes comme reconnaître des objets, identifier une personne sur une photo, conduire une voiture, etc.
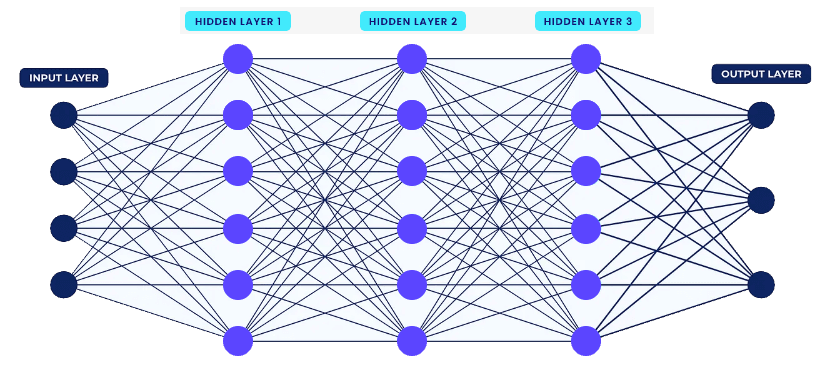
Les réseaux de neurones sont basés sur l’idée de connexions neuronales. Chaque nœud peut être connecté à différents nœuds dans plusieurs couches. Un réseau neuronal possède une couche d’entrée, qui est la couche où les données en entrée sont saisies, une couche de sortie qui contient toutes les données en sortie possibles et une ou plusieurs couches cachées qui effectuent un traitement mathématique. Chaque couche de nœuds s’entraîne sur des données en fonction de la sortie de la couche précédente.
Les réseaux neuronaux profonds (Deep neural networks), responsables de l’apprentissage profond, sont constitués de couches de nœuds, contenant une couche d’entrée, une ou plusieurs couches cachées (hidden layer) et une couche de sortie.
Outils de Machine Learning et Deep Learning
Il existe plusieurs outils d’apprentissage automatique disponibles, voici une brève description des plus populaires d’entre eux.
Bibliothèques Python

Scikit-learn est destinée au développement de Machine Learning en Python. Il fournit une bibliothèque pour le langage de programmation Python.
TensorFlow est une bibliothèque JavaScript qui aide à mettre en place de l’apprentissage automatique. Ses API permettent de construire et de former des modèles de Deep Learning.
Keras est une API pour le Deep Learning. Elle permet d’effectuer des recherches rapides avec Python.
Services et plateformes de Machines Learning

La concurrence fait rage ces dernières années entre les grands éditeurs et les fournisseurs du cloud public qui se positionnent de plus en plus dans le domaine de l’IA en proposant une panoplie de produits et services :
IBM Machine Learning : permet de combiner plusieurs produits différents, comme IBM Watson Studio, IBM Watson Machine Learning, IBM Watson OpenScale et IBM Cloud Pak for Data. Les utilisateurs sont en mesure de créer des modèles d’IA à l’aide d’outils open source, de déployer des modèles d’IA avec leurs applications et de surveiller les modèles d’IA.
IBM Machine Learning coûte à partir de 0,50 $/heure et propose un essai gratuit de 30 jours.
Azure Machine Learning de Microsoft permet aux utilisateurs de créer, former et déployer rapidement et facilement des modèles d’apprentissage automatique.
Azure Machine Learning coûte à partir de 0,33 $/heure et offre 12 mois gratuits avec un crédit de 200 $.
La plateforme Google Cloud AI réunit sa plateforme AI, AutoML et MLOps pour une expérience complète et unifiée. Leur plateforme s’adapte au niveau de compétence de l’utilisateur, offrant à la fois une science des données en point-and-click avec AutoML et une optimisation avancée des modèles.
Google Cloud AI Platform coûte à partir de 0,19 $/heure et offre un crédit gratuit de 300 $ pour les 90 premiers jours.
Amazon Machine Learning permet aux utilisateurs de créer, déployer et exécuter des applications d’apprentissage automatique dans le cloud via AWS. Vous pourrez profiter du traitement du langage naturel (NLP), de la reconnaissance d’images basée sur l’apprentissage profond et d’autres services en un seul clic.
Amazon Machine Learning coûte à partir de 0,42 $/heure et propose un essai gratuit de 12 mois.
Jupyter Notebook est une application web open-source qui permet aux utilisateurs de créer, tester et exécuter des codes python. Il est simple d’illustrer, de visualiser et de tester un code ligne par ligne. Il est utilisé pour la modélisation des données, la visualisation statistique et les programmes d’apprentissage automatique.
Google Colab est un notebook sur cloud qui supporte Python. Il permet de créer des applications d’apprentissage automatique à l’aide des bibliothèques PyTorch, Keras, TensorFlow et OpenCV.
Anaconda est l’un des outils les plus populaires pour les data scientists afin de développer des projets d’apprentissage automatique sur une seule plateforme. Il est composé des plus fameux éditeurs pour Python et R comme Pycharm, Rstudio, Spyder, Jupyter, etc. Il est livré avec plus de 150 bibliothèques scientifiques destinées aux Statistiques/ML/Visualisation pour former et visualiser les données/rapports.
Conclusion
A travers cet article, nous avons présenté les concepts de base de l’apprentissage automatique, l’apprentissage profond et de l’intelligence artificielle ainsi que les principaux outils, plateformes et services y associés.
Dans les prochains articles, nous allons rentrer dans le détail de ces concepts en présentant un projet d’apprentissage automatique que nous avons développé chez Xelops Technology ainsi que les étapes de base pour mettre en place ce projet.
Bibliographie
- AI For Everyone par deeplearning.ai sur https://www.coursera.org/
- Machine Learning par Université de Stanford sur https://www.coursera.org/
- Deep Learning sur https://machinelearnia.com/
- https://www.trustradius.com/machine-learning
- https://theqalead.com/tools/machine-learning-software/
- https://blog.devgenius.io/what-is-deep-learning-2a4d1db4a26b
- Neural Networks par IBM sur https://www.ibm.com/cloud/learn/neural-networks/

















