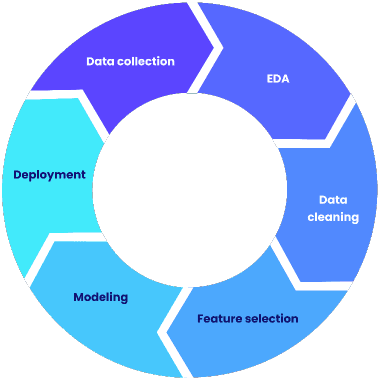
Cycle de vie d’un projet de Machine Learning
 Data
Data
Le Machine Learning permet de développer, tester et appliquer des algorithmes d’analyse prédictive sur différents types de données, afin de prédire l’avenir. Dans cet article, nous allons découvrir les différentes phases de développement d’un projet d’apprentissage automatique, sans aller au fond des choses.
1 — Collecte des données (Data collection)
Dans l’apprentissage machine, il est important de considérer l’importance de la collecte de données. Si nous disposons d’un plus grand nombre de données, il est plus probable que l’algorithme de machine learning puisse les comprendre et donner des prédictions précises sur les données invisibles.
Lorsque nous demandons finalement à la machine de faire une prédiction, elle utilise les connaissances et l’expérience précédentes recueillies à partir des données fournies.
Par conséquent, les données pour l’apprentissage machine sont essentielles pour développer son expérience et sa capacité de prise de décisions.
2 — Exploration de données (EDA)
EDA ou Exploratory Data Analysis est une façon de visualiser, de résumer et d’interpréter les informations qui sont cachées dans les données collectées.
L’EDA est l’une des étapes cruciales de la science des données, qui nous permet d’obtenir certaines informations et mesures statistiques essentielles, pour assurer la continuité de la construction de notre modèle. Elle permet d’avoir une meilleure compréhension des variables d’un ensemble de données ainsi que les relations qui existent entre elles.
3 — Nettoyage des données (Data cleaning)
Le nettoyage des données est le processus qui consiste à préparer les données, pour l’analyse par la suppression ou la modification des données qui sont incorrectes, incomplètes, non pertinentes, dupliquées ou mal formatées.
La plupart du temps est consacré au nettoyage, plutôt qu’au développement du modèle d’apprentissage, et la plupart des data scientist passent énormément de temps à améliorer la qualité des données. La raison pour laquelle il s’agit de l’étape la plus importante si on veut faire des prédictions fiables.
La préparation des données vous aide à maintenir la qualité et permet des analyses plus précises, ce qui favorise une prise de décision efficace et intelligente.
4 — Sélection des variables explicatives (Feature selection)
Feature Selection est la méthode qui consiste à choisir les informations importantes de nos données. Pour former un modèle optimal, il faut s’assurer d’utiliser uniquement les caractéristiques essentielles.
Les caractéristiques inutiles et redondantes ne ralentissent pas seulement le temps d’apprentissage, mais elles affectent également les performances.
Les méthodes de sélection des caractéristiques permettent de résoudre ces problèmes en réduisant les dimensions sans perte significative de l’information totale. Elles permettent également de donner un sens aux caractéristiques et à leur importance.
5 — Modélisation (Modeling)
Au cours de cette étape, il faut entraîner de nombreux modèles parmi une collection de modèles d’apprentissage automatique candidats, sur les données préparées pour définir celui qui fournit les prédictions les plus fiables.
Après avoir formé notre modèle, nous avons besoin de vérifier sa performance et d’essayer de l’évaluer.
6 — Déploiement (Deployment)
C’est la dernière étape du cycle de vie de l’apprentissage automatique, qui couvre la mise en production de notre modèle ML.
Mais le travail ne s’arrête pas là, nous devons suivre les performances du modèle déployé, en l’alimentant par de nouvelles données, pour s’assurer qu’il continue à faire le travail avec la qualité attendue.
Conclusion
Dans cet article, nous avons découvert les étapes nécessaires dans le cycle de vie complet d’un projet de Machine Learning ainsi que l’importance de chacune d’elles.
Dans le cadre des prochains articles, nous discuterons de chaque étape à l’aide des exemples en python d’une manière plus profonde et plus développée.
















