Comment réduire la complexité de vos données tout en préservant l’essentiel
5min read • 2025-06-16 Data
Data
Data
Quand on travaille avec des données complexes, il est courant d’être confronté à un problème de « trop » : trop de colonnes, trop de dimensions, et au final, trop de bruit. Ce genre de complexité peut ralentir les modèles d’intelligence artificielle (IA), rendre les calculs inefficaces, et augmenter le risque de surapprentissage. Heureusement, il existe des solutions puissantes comme le PCA (Principal Component Analysis) pour réduire cette complexité sans perdre l’essentiel de l’information. Dans cet article, nous allons explorer comment le PCA a été utilisé pour simplifier des données complexes tout en préservant 95 % de leur information.
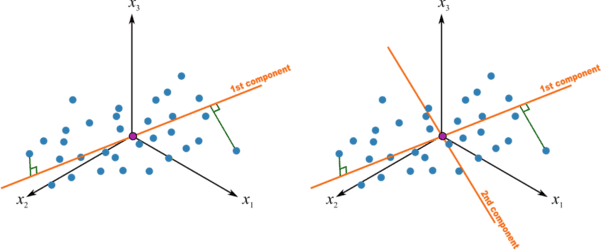
Source de l’image: « Understanding the Mathematics behind Principal Component Analysis », Fritz.ai, 2023.
Le problème de la haute dimensionnalité
Prenons un exemple concret : un dataset ayant COULEUR comme attribut. Dans ces données, la colonne COULEUR contient 22 couleurs différentes, telles que rouge, bleu, vert, bordeaux, etc., représentant différentes teintes. Pour rendre ces catégories compréhensibles pour un modèle d’IA, on applique souvent un encodage one-hot, où chaque valeur unique est transformée en une colonne binaire. Cependant, ce processus crée 22 nouvelles colonnes, augmentant la dimensionnalité des données.
Conséquences :
- Inefficacité computationnelle : Les modèles prennent plus de temps à s’entraîner.
- Risque de surapprentissage : Les modèles peuvent apprendre des motifs bruités plutôt que les relations générales.
- Corrélations inutiles : Certaines colonnes deviennent redondantes, ajoutant du bruit.
C’est là que le PCA intervient pour simplifier les choses.
La magie de la simplification des données
Le PCA (Principal Component Analysis) est une technique mathématique qui transforme vos données en un nouvel ensemble de variables appelées composantes principales. Ces composantes sont des combinaisons linéaires des variables initiales, calculées pour capturer un maximum de variance (information) tout en étant orthogonales (sans redondance).
Voici les étapes clés de PCA :
- Standardisation des données : Chaque colonne est transformée pour avoir une moyenne de 0 et un écart-type de 1, ce qui évite qu’une colonne à grande échelle domine les calculs.
- Matrice de covariance : Le PCA commence par calculer la matrice de covariance, qui capture les relations entre les variables/colonnes initiales.
- Décomposition en valeurs propres : La matrice de covariance est ensuite décomposée pour obtenir des valeurs propres (eigenvalues) et des vecteurs propres (eigenvectors). Voici ce que cela signifie :
- Les valeurs propres représentent la proportion de variance expliquée par chaque direction (composante principale).
- Les vecteurs propres indiquent les directions des nouvelles composantes principales dans l'espace des données.
- Tri et réduction de dimensions : Les composantes principales sont triées par importance (en fonction de leurs valeurs propres). On conserve uniquement les composantes principales expliquant un seuil défini de la variance cumulée, par exemple 95 %.
Exemple :- Si la première composante explique 40 % de la variance, la deuxième 30 %, et la troisième 25 %, on peut garder ces trois composantes pour atteindre 95 % de variance expliquée. Si 70% de variance nous suffit, on peut prendre que les deux premières composantes.
Déterminer le nombre optimal de composantes
Pour savoir combien de composantes principales à garder, on peut utiliser une méthode simple et visuelle : la courbe de la variance cumulée expliquée. Cette courbe montre la part d’information (ou variance) capturée par chaque composante principale, additionnée au fur et à mesure.
L’objectif est de choisir un nombre de composantes qui capture la majorité de l’information, souvent entre 90 % et 95 %. Par exemple :
- Si les 8 premières composantes expliquent 95 % de la variance, cela signifie qu’elles contiennent presque toute l’information utile des données initiales.
- Les composantes restantes, qui expliquent seulement 5 % de la variance, peuvent être ignorées car elles apportent peu d’information supplémentaire.
En testant différents seuils (90 %, 95 %, etc.), vous pouvez trouver le bon équilibre entre réduire la taille des données et garder assez d’information pour que vos modèles soient performants. Si un modèle fonctionne mieux avec un seuil plus bas, vous pouvez ajuster en conséquence. Cette méthode est donc un moyen pratique d’optimiser à la fois vos données et vos résultats.
Application du PCA à l’attribut COULEUR
Prenons le cas de l’attribut COULEUR mentionné précédemment, où chaque valeur unique a été encodée en une colonne binaire (one-hot encoding). Cela a généré un total de 22 colonnes. Après application du PCA, les résultats suivants ont été obtenus pour les 8 premières composantes principales :
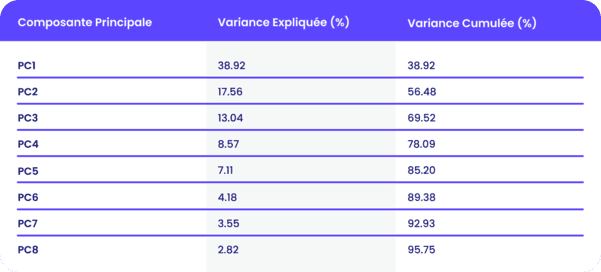
Pour mieux comprendre ces résultats, voici un graphique illustrant la variance cumulée expliquée par les composantes principales :
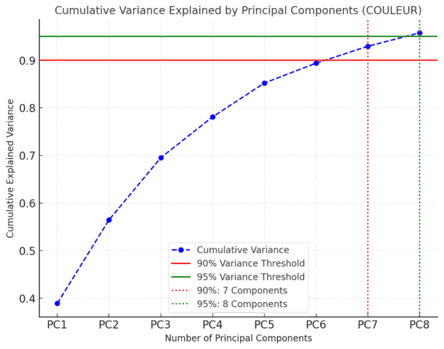
- Ligne rouge horizontale : Seuil de 90 % de variance expliquée.
- Ligne verte horizontale : Seuil de 95 % de variance expliquée.
- Lignes verticales pointillées :
- À 90 % : 7 composantes principales suffisent.
- À 95 % : 8 composantes principales sont nécessaires.
Les avantages concrets du PCA
Voici les avantages observés après l’application du PCA :
- Simplification : Le passage de 22 colonnes à 8 composantes principales a amélioré l’efficacité computationnelle et la clarté du modèle.
- Variance préservée : Les 95 % de variance expliquée garantissent que les motifs les plus importants des données sont toujours présents.
- Orthogonalité : Les nouvelles composantes étant non corrélées, elles éliminent tout problème de multicolinéarité.
Visualiser le PCA dans l’espace des données:
Pour mieux comprendre le PCA, imaginez un espace à 22 dimensions – c’est ainsi que vos données avec 22 colonnes sont représentées. Dans cet espace, le PCA cherche à simplifier les choses en trouvant les axes principaux qui capturent le plus d'informations.
- Premier axe : Le PCA identifie l’axe où les données sont le plus dispersées, c’est-à-dire celui qui contient la majorité de l’information. Lorsque vos données sont projetées sur cet axe, on capte déjà beaucoup de leur structure.
- Deuxième axe : Ensuite, le PCA cherche un deuxième axe, perpendiculaire (ou orthogonal) au premier. Cet axe capture autant d’information que possible, tout en étant indépendant du premier.
- Troisième axe, quatrième, etc. : Le processus continue, avec chaque nouvel axe capturant une part supplémentaire de l’information restante, jusqu’à ce que l’essentiel de la variance des données soit représentée.
Conclusion: La beauté dans la simplicité
Le PCA, c’est l’exemple parfait de la beauté dans la simplicité. Il transforme un labyrinthe de données complexes en un chemin clair et direct, tout en conservant l’essence même de l’information. Réduire 22 colonnes à 8 composantes principales sans perdre 95 % de la variance, c’est un peu comme faire de l’art avec des mathématiques.
Dans les projets d’IA, il n’est pas toujours nécessaire de tout garder. Trouver ce qui est essentiel et se débarrasser du reste, c’est là que réside la magie – et, avouons-le, la vraie beauté. Simplifiez, testez, et admirez les résultats.
Références
https://scikit-learn.org/stable/modules/decomposition.html
https://www.cs.cmu.edu/~elaw/papers/pca.pdf
















